By Evan Norman,
Web Specialist, McElroy Translation,
Austin, Texas 78701 USA
quotes[at]mcelroytranslation.com
http://www.mcelroytranslation.com/
Web 2.0 vs. your business model
McElroy has modified its translation/review/client review process considerably as the type of material being translated continues to evolve from traditional documentation that is routed through a linear channel, to ongoing updates of data that require instant communication between many parties to achieve translation of content.
Along with the type of material being translated changing, client expectations have also changed. Increasingly, clients who author and review their content want to be integrated into the process, which has “webified” the way we collaborate on projects.
For these translators, project managers and clients who are migrating away from strictly email and phone interaction, the McElroy team is evolving and adapting to collaborating within online workspaces, like Wikis for instance.
Wiki as a project management tool for translation and localization
A Wiki is an invaluable tool for any localization endeavor, since you can easily and in many cases securely communicate with users all over the world using a browser interface. Generally a Wiki can be set up to use the least bandwidth necessary, particularly for internal communication, which makes it an excellent tool when traveling or for users in locales that don’t support broadband.
Along with McElroy’s project tracking system and other tools, we use a Wiki for project management, planning and collaborative documentation. Using a Wiki is a quick way for users in different locales and of varying levels of technical expertise to effectively communicate, ascertain project status and get the latest updates to living documents.
A CMS/workflow system for Web 2.0
Isn’t machine translation good enough?
The perfect translation, would, of course, be 100% accurate, instant and free. Though instant and free or relatively cheap, machine translation tools demonstrate at best 50% accuracy.
McElroy recently reviewed several software companies that offer automatic translation of your blog or website into a dozen different languages. Developers of the software take advantage of Google’s Translator API, which automatically translates websites. The machine-translated site is then indexed in a language-coded directory to assist the website owner with increasing “multilingual search engine traffic.”
Communicating with your international customers this way would be like flipping a coin every time you spoke to them. Heads, they understand your product/marketing information the way it was intended to be understood, tails, they read gibberish, or worse, take offense and use a competitor. For instance, “A Couple Of Killer Internet Marketing Techniques” gets translated as “A pair of the techniques of the commercialization of the Internet of the assassin” when taken into Spanish. Unless your target audience is interested in how Spanish-speaking assassins are commercializing the Internet, any search engine traffic generated from such nonsense will be irrelevant to your business.
(For giggles:
Korean - 2 murderer Internet selling and buying techniques
Italian - One brace of the techniques of sale of the Internet of the assassin
German - A pair of the murderer Internet marketing techniques)
Content Management Systems (CMS)/human translation workflow models of the past involved a lengthy, linear “round trip” process of entire blocks of content into the desired languages each time updates were made, in order to ensure accuracy across all languages. Over time, the cost and labor-intensity of this process causes many of the desired languages to fall completely out-of-sync with the most recent updates to content, rendering product information that is inaccurate or downright false, sometimes resulting in expensive legal action taken against the corporate creator of the content. As content authoring becomes more fragmented and prolific, especially in the world of Web 2.0, new tools and models are required to ensure that these problems do not occur.
Since many corporate departments do not have the luxury of completely scrapping legacy, high-dollar CMS solutions (that are not optimal for Web 2.0 content authoring/localization) in favor of new ones, Leepfrog’s and McElroy Translation’s CMS/Translation workflow solutions, combine to readily offer a lightweight and nimble alternative that can even reside as a layer between the legacy CMS and what your visitor sees in the web browser.
Pagewizard
Pagewizard is a CMS our partner Leepfrog built recently with McElroy’s input to reflect the evolving needs of clients on the web. Web visitors who arrive at sites served up by the Pagewizard CMS will see a truly localized version of the site based upon their language preferences, rather than an English website with a few multilingual page add-ons.
McElroy’s client Emerson Processes wanted its content authors, (English) content reviewers, translation team, and in-country reviewers to all play well together under a unified content management/translation structure. Emerson’s content authoring/translation process requirements are scattered, both in the sense of the physical location of the authors/translators/users of content, as well as the particular amount of content that the corporate office needed authored/translated for a particular location at a particular time. If all players were not operating under one unified structure, the end result would be a website full of stale content, and endless confusion throughout the ongoing process of content authoring/translation would reign.
Emerson Processes sources translation to McElroy and web architecture/CMS to Leepfrog. Emerson Processes, McElroy and Leepfrog are working together to accomplish a goal that satisfies all of the above criteria.
As a result, McElroy and Leepfrog were able to create a CMS/TM system that was lightweight and versatile for use by mid-sized companies. The PageWizard CMS is versatile enough to sit on top of legacy “heavy” CMS’s that some companies have invested too much in to part with. Its nimbleness also makes it a perfect CMS solution for Web 2.0-type business models, where user-authored content is generated constantly and updated frequently.
The PageWizard CMS can help manage content translation, either through a language service provider or leveraging in-house translators. As content is changed in the primary language, the PageWizard groups together sets of changes and dispatches them to the translators.
PageWizard coordinates directly with ELJOTS®, McElroy’s project tracking system, allowing for much lower per-word translation costs than providing translations manually. PageWizard tracks changes while the primary content is being translated, and can control the size of the batches to minimize the per-word cost of translation.
PageWizard can handle urgent changes – such as updating incorrect published information – in a different way than standard changes. Different pages may be flagged for different sets of target languages, providing flexibility within a budget. PageWizard will automatically re-use shared content, such as site navigation.
The net effect of the PageWizard and translation services team is to present an accurate, up-to-date version of a site’s content in the most preferred language of the website visitor, with little additional effort on the part of the content authors or the site’s editors.
Some of the features of PageWizard include:
* scattered translation workflow— multilingual content is efficiently maintained and updated after initial push
* re-use of shared translated content
* flexible presentation, based on availability of translated content
* language-specific templates, or parts of templates
* potential to instantly remove inaccurate content to avoid legal issues
* automatic handling of non-translated changes
* leveraging of translation memory
* word count driving workflow
* language batching
* minimization of per-word translation costs
* limiting content sent to only what is to be translated
* avoidance of difficult scripts that “break” translation tools
* ability to self-publish each web page at end of translation process
Conclusion
Clients’ evolving needs have changed the landscape for integrating how language service provider teams and their clients collaborate with each other. These changing needs have influenced how our team and workflow system have adapted to meet the challenge—as well as how McElroy continues to explore and develop new ways for translation project teams to collaborate online.
Leepfrog's CEO Lee Brintle and McElroy's Project Manager Rainy Day contributed to the contents of this article
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Showing posts with label computer translation. Show all posts
Showing posts with label computer translation. Show all posts
Wednesday, June 3, 2009
Tuesday, June 2, 2009
Translation memory 2.0
By Jonathan Kirk,
CEO and founder, Elanex
I could have sworn I translated that just last week …’ is the all too familiar mantra of any translator, especially an in-house corporate translator, where repeated and similar translations are very common due to corporate standards and job similarities. Thankfully, this mantra is now close to extinct with the advent of powerful desktop translation memory solutions from a number of vendors over the last decade. For any individual translator, it is easy to find material you have already translated; for a group of translators working closely together, it is relatively easy to find material created by anyone in the group, provided certain work practices are observed, and the software is carefully configured.
But two key problems remain: for any company, translation remains an extremely expensive proposition – it can often double the cost of a website or of creation of marketing materials. On a larger scale, the whole translation ecosystem today is inefficient: vast quantities of the world’s written material have yet to be translated, while the small quantity of material that actually has been translated contains large quantities of similar material, all paid for independently by individual private firms.
In other words, the same sort of problem exists in the translation industry that existed in the early days of the internet: lots of valuable, useful information exists, but where is it? Interestingly enough, the solution may also be the same: a centralized, easily searchable, easy to use repository – in this case, of the world’s translations.
Elanex TSE (Translation Search Engine)
The biggest benefit of translation memory is not the tool itself, but the actual content: in other words, the memory. For most translators purchasing a translation memory system is equivalent to purchasing a word processor – it’s very convenient when you want to write an article, but it doesn’t actually write the article for you.
 Part of the reason is technology – creating, managing, and quickly searching a gigantic database containing tens, hundreds or even thousands of millions of sentences was an impractical proposition ten years ago.
Part of the reason is technology – creating, managing, and quickly searching a gigantic database containing tens, hundreds or even thousands of millions of sentences was an impractical proposition ten years ago.
A bigger reason was the ‘paradigm’ that existed when translation memory first arrived – most software was still installed on local computers, and the software itself did not typically communicate with software installed on other computers.
Perhaps the biggest reason of all, though, is that in an industry where translators create and sell ‘words for a living’, re-using the words they create is seen as the right to earn a return on the investment made by the creator. If a translator can re-use an existing translation for a new client, the translator has saved some time, and therefore made more money. For a company, this rationale is different; the company can save dramatically by not having to translate the same words and phrases again when they appear in new documents.
However, the world has changed – in many ways – and a better solution is now available: the TSE (for Translation Search Engine).
A new paradigm emerges
The watchwords in today’s emerging society are ‘networked’, ‘open source’, ‘software as a service’, ‘usergenerated content’ and so on. The key transition is that in a networked economy, it makes the most sense for people to have access to and build on the work of others, whereas in a closed economy, it made the most sense for people to act as ‘gatekeepers’ to their own private repositories of information. Hence, intellectual property of many kinds is moving to an ‘open source’ kind of model – where companies can still ‘sell’ the software (by providing value-added services on top of it – think RedHat, MySQL or SugarCRM), but where the intellectual property itself is free– (as in freedom of speech) –ly available for all to improve and extend.
In the case of the TSE, this principle enables a whole new alternative for companies and translators: access to a gigantic repository of existing high quality translations, which through the power of pattern matching (or ‘fuzzy’ matching as it’s typically known in a translation memory context), can be re-used to reduce or eliminate new translation.
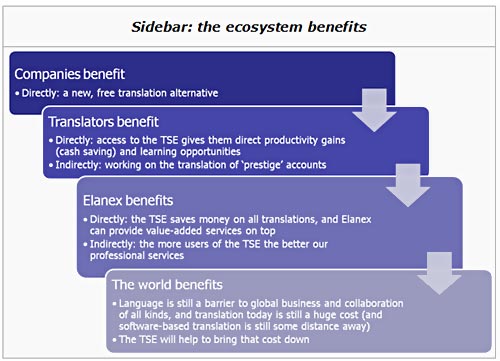
For companies, the benefit is obvious – the TSE provides a brand new way of getting high quality translation done, which provides the ‘best of both worlds’ when compared to the two main existing solutions today (fully human translation, and fully automated translation): the translation quality is high, since it was created by humans; the cost is greatly reduced, since much of the heavy lifting has already been done.
For individual translators, the benefit is also clear – if translation memory systems which contain no prior translations off-the-shelf are useful, then the same system pre-loaded with millions of top quality translations for a freelancer to leverage would be infinitely more useful. In our own tests, the TSE currently saves around 5% of a translator’s time – which may not sound like much, but it ‘translates’ (if you’ll pardon the pun) to around a day a month, which is a pretty significant productivity gain for anyone.
What is less obvious is that the ecosystem as a whole benefits. The TSE does not ‘eliminate translator jobs’ – far from it. Only a tiny, tiny fraction of the world’s content is available today in multiple languages – most websites are still in the language of their creator only; most of the world’s intellectual property (in the form of patents, academic theses and papers and so on) is still in a handful of languages at best; even most of the world’s news remains untranslated. As long as content remains untranslated, there are commercial opportunities not yet being exploited; by making it cheaper for companies to exploit those opportunities, the ‘rising tide floats all boats’.
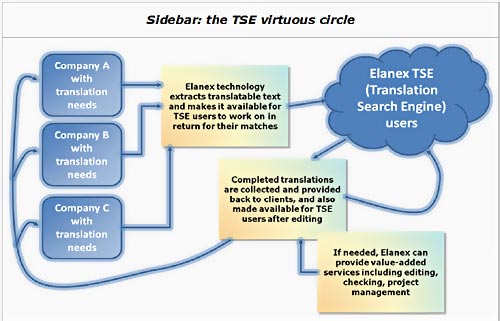
And who pays for it?
As with open source software, the first question is ‘if it’s free, who pays for it?’, and the answer is also the same: the basic rules of economics still apply, but a level of indirection has been introduced which makes a new system work.
In the case of the TSE, when translators search within the TSE for matches to existing translations, the TSE will only return matches if they’re actually found (unlike an automated translation solution, which would come up with its ‘best guess’ for every sentence). Instead of paying for these matches, users contribute their own translations, translations of items presented by the TSE to the translator, or other types of work such as editing other contributions.
In other words, a translator’s benefit is clear – an extra productive day per month. In return for this benefit, the translator is contributing more content – in turn making the system more useful for other translators. A company benefits from free or low cost translation – and all that is required in turn is to allow the human translators who do the rest of the work to put that material into the TSE.
With no extra cost to anyone, and with savings for both translators and companies, a system has emerged which makes the whole translation process more efficient.
Where will it all end?
Today’s fully automated ‘machine translation’ solutions rely on statistical techniques for analyzing large bodies of text. This is an improvement over first generation ‘rulebased’ systems, which could not develop sophisticated enough ‘rules’ for how humans actually construct sentences – one of the reasons it’s an improvement is that since the source material for statistical systems is real translation, the material generated by the systems sounds more natural, even if it’s wrong (somehow the mistakes are more ‘human’, in the same way that typing errors made by humans are more natural than the type of errors made by OCR software).
 However, statistical analysis is not how humans talk – humans use language as a representation of how they think, and the language they create has all the flexibility of thought itself. Computers are still some distance from replicating thought.
However, statistical analysis is not how humans talk – humans use language as a representation of how they think, and the language they create has all the flexibility of thought itself. Computers are still some distance from replicating thought.
Translation memory therefore provides an alternative rather similar to the approach Big Blue takes to chess – a form of brute force. If you can’t create a translation, then look it up!
Translation is a barrier to international trade, to global communication, and lack of it is one reason why some cultures have a hard time understanding each other. Anything that can be done through technologies such as the TSE to reduce translation costs – especially if they do not destroy a thriving human industry as an accidental byproduct – can ultimately help to make the world a better place.
Jonathan Kirk
Elanex CEO and founder
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
CEO and founder, Elanex
I could have sworn I translated that just last week …’ is the all too familiar mantra of any translator, especially an in-house corporate translator, where repeated and similar translations are very common due to corporate standards and job similarities. Thankfully, this mantra is now close to extinct with the advent of powerful desktop translation memory solutions from a number of vendors over the last decade. For any individual translator, it is easy to find material you have already translated; for a group of translators working closely together, it is relatively easy to find material created by anyone in the group, provided certain work practices are observed, and the software is carefully configured.
But two key problems remain: for any company, translation remains an extremely expensive proposition – it can often double the cost of a website or of creation of marketing materials. On a larger scale, the whole translation ecosystem today is inefficient: vast quantities of the world’s written material have yet to be translated, while the small quantity of material that actually has been translated contains large quantities of similar material, all paid for independently by individual private firms.
In other words, the same sort of problem exists in the translation industry that existed in the early days of the internet: lots of valuable, useful information exists, but where is it? Interestingly enough, the solution may also be the same: a centralized, easily searchable, easy to use repository – in this case, of the world’s translations.
Elanex TSE (Translation Search Engine)
The biggest benefit of translation memory is not the tool itself, but the actual content: in other words, the memory. For most translators purchasing a translation memory system is equivalent to purchasing a word processor – it’s very convenient when you want to write an article, but it doesn’t actually write the article for you.
A bigger reason was the ‘paradigm’ that existed when translation memory first arrived – most software was still installed on local computers, and the software itself did not typically communicate with software installed on other computers.
Perhaps the biggest reason of all, though, is that in an industry where translators create and sell ‘words for a living’, re-using the words they create is seen as the right to earn a return on the investment made by the creator. If a translator can re-use an existing translation for a new client, the translator has saved some time, and therefore made more money. For a company, this rationale is different; the company can save dramatically by not having to translate the same words and phrases again when they appear in new documents.
However, the world has changed – in many ways – and a better solution is now available: the TSE (for Translation Search Engine).
A new paradigm emerges
The watchwords in today’s emerging society are ‘networked’, ‘open source’, ‘software as a service’, ‘usergenerated content’ and so on. The key transition is that in a networked economy, it makes the most sense for people to have access to and build on the work of others, whereas in a closed economy, it made the most sense for people to act as ‘gatekeepers’ to their own private repositories of information. Hence, intellectual property of many kinds is moving to an ‘open source’ kind of model – where companies can still ‘sell’ the software (by providing value-added services on top of it – think RedHat, MySQL or SugarCRM), but where the intellectual property itself is free– (as in freedom of speech) –ly available for all to improve and extend.
In the case of the TSE, this principle enables a whole new alternative for companies and translators: access to a gigantic repository of existing high quality translations, which through the power of pattern matching (or ‘fuzzy’ matching as it’s typically known in a translation memory context), can be re-used to reduce or eliminate new translation.
For companies, the benefit is obvious – the TSE provides a brand new way of getting high quality translation done, which provides the ‘best of both worlds’ when compared to the two main existing solutions today (fully human translation, and fully automated translation): the translation quality is high, since it was created by humans; the cost is greatly reduced, since much of the heavy lifting has already been done.
For individual translators, the benefit is also clear – if translation memory systems which contain no prior translations off-the-shelf are useful, then the same system pre-loaded with millions of top quality translations for a freelancer to leverage would be infinitely more useful. In our own tests, the TSE currently saves around 5% of a translator’s time – which may not sound like much, but it ‘translates’ (if you’ll pardon the pun) to around a day a month, which is a pretty significant productivity gain for anyone.
What is less obvious is that the ecosystem as a whole benefits. The TSE does not ‘eliminate translator jobs’ – far from it. Only a tiny, tiny fraction of the world’s content is available today in multiple languages – most websites are still in the language of their creator only; most of the world’s intellectual property (in the form of patents, academic theses and papers and so on) is still in a handful of languages at best; even most of the world’s news remains untranslated. As long as content remains untranslated, there are commercial opportunities not yet being exploited; by making it cheaper for companies to exploit those opportunities, the ‘rising tide floats all boats’.
And who pays for it?
As with open source software, the first question is ‘if it’s free, who pays for it?’, and the answer is also the same: the basic rules of economics still apply, but a level of indirection has been introduced which makes a new system work.
In the case of the TSE, when translators search within the TSE for matches to existing translations, the TSE will only return matches if they’re actually found (unlike an automated translation solution, which would come up with its ‘best guess’ for every sentence). Instead of paying for these matches, users contribute their own translations, translations of items presented by the TSE to the translator, or other types of work such as editing other contributions.
In other words, a translator’s benefit is clear – an extra productive day per month. In return for this benefit, the translator is contributing more content – in turn making the system more useful for other translators. A company benefits from free or low cost translation – and all that is required in turn is to allow the human translators who do the rest of the work to put that material into the TSE.
With no extra cost to anyone, and with savings for both translators and companies, a system has emerged which makes the whole translation process more efficient.
Where will it all end?
Today’s fully automated ‘machine translation’ solutions rely on statistical techniques for analyzing large bodies of text. This is an improvement over first generation ‘rulebased’ systems, which could not develop sophisticated enough ‘rules’ for how humans actually construct sentences – one of the reasons it’s an improvement is that since the source material for statistical systems is real translation, the material generated by the systems sounds more natural, even if it’s wrong (somehow the mistakes are more ‘human’, in the same way that typing errors made by humans are more natural than the type of errors made by OCR software).
Translation memory therefore provides an alternative rather similar to the approach Big Blue takes to chess – a form of brute force. If you can’t create a translation, then look it up!
Translation is a barrier to international trade, to global communication, and lack of it is one reason why some cultures have a hard time understanding each other. Anything that can be done through technologies such as the TSE to reduce translation costs – especially if they do not destroy a thriving human industry as an accidental byproduct – can ultimately help to make the world a better place.
Jonathan Kirk
Elanex CEO and founder
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Monday, June 1, 2009
Avoid getting lost in translation
By Michael Hamilton,
Vice President of Product Management,
MadCap Software
Where did my table of contents go? What happened to my glossary? These questions, and many others about document structure and formatting, still arise all too often as these components get lost in translation.
We have seen important technology advances to facilitate the translation of content. Most notable are the growing use of Unicode to support both single- and double-byte languages and adoption of the Extensible Markup Language (XML), which facilitates the sharing of structured data across different systems. As a result, translating a set of words from one language into one or more others is a fairly predictable experience.
Bringing that predictability to the overall document remains a challenge. At the heart of the matter is the fact that document files need to be transferred into a translation memory system (TMS). A TMS can be programmed to recognize the document formatting. However, when localization experts transfer files into these pre-programmed systems, portions of those files-for example variables and indices-often get corrupted.
Even when the actual file transfer is smooth, the fact that there is a transfer leaves room for error and inefficiency. The challenge can be particularly daunting with topic-based authoring. Consider that some projects may have 12,000 files. The project manager needs to ensure that all 12,000 files get sent over for translation and localization. It is not uncommon to get the translation back, and realize that, for example, an index has not been translated. Now the localization project is delayed as the additional file is translated.
Then, too, if there are changes to an existing document, perhaps to reflect a policy change or product upgrade, it may be that only 112 of the 12,000 files need to be updated and translated. It can take hours for the project manager to identify that small subset of files, and hopefully he or she will catch them all.
Translation Without File Transfers
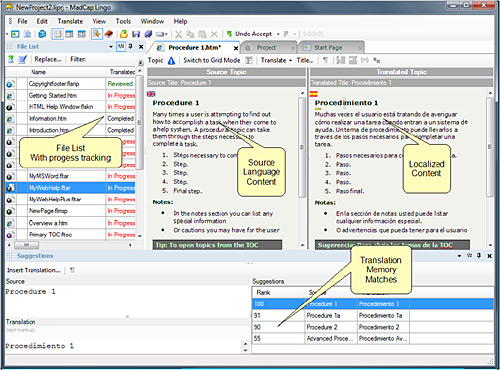
So many of these challenges would disappear if there was no need to actually transfer the data. This is the approach taken with MadCap Lingo, a fully integrated translation memory system and authoring tool that eliminates the need for file transfers in order to complete translation. As a result, documentation and localization professionals no longer have to risk losing valuable content and formatting. Instead, document components-such as tables of contents, topics, index keywords, concepts, glossaries, and variables-all remain intact throughout the translation and localization process, so there is never a need to recreate them. The XML-based MadCap Lingo is also fully Unicode enabled to support any European or Asian language.
MadCap Lingo is tightly integrated with MadCap Flare, a native-XML authoring product, and MadCap Blaze, a native- XML alternative to Adobe FrameMaker for publishing long print documents, which will be generally available in early 2008. A user simply creates a MadCap Lingo project to access the source content in a Flare or Blaze project via a shared file structure. Working through Lingo's interface, the user accesses and translates the content. Because the content never actually leaves the structure of the original Flare or Blaze project, all the content and formatting are preserved in the translated version. Once a project is translated, it is opened in either Flare or Blaze, which generates the output and facilitates publishing.
Taking the file transfer out of translation simplifies and speeds the localization process in many ways. Because there is no transfer, all files are automatically translated; none are left behind. There also is a clear view of all the files that need to be translated. When a MadCap Lingo project is initiated, it automatically lists all of the files in the documentation project. Because the software automatically tracks what files have and haven't been translated, it will recognize if the project is an update to an earlier one, highlighting the files that have been changed and therefore require translation.
With this in mind, let's revisit the example of a project containing 12,000 content files. By allowing the translation to occur within the original project, all 12,000 files are automatically flagged for localization-as well as any support files, such as a table of contents or a list of variables-providing a complete picture of the project. Moreover, when there is an update that affects only 112 files, it is easy for a documentation or localization expert to immediately identify and then translate just those files rather than having to sift through the entire list. Project managers can ensure that their projects are complete while eliminating hours of unnecessary work.
Similarly, project managers often receive an eleventh- hour change that requires only one or two sentence adjustments. With the integrated translation memory system, a documentation or translation expert can quickly make the updates. If the updates affect variables in the project, those variables will be updated automatically as well, making it possible to meet publishing deadlines even with last-minute edits.
The ability to complete translation within the content project means that document and localization professionals can view content as it will be published with the table of contents, images, screen captures, and more. They also can review the original language version and the translated version side by side for comparison. This facilitates the ability to address formatting issues that arise from the translation.
For example, German text strings tend to be longer than English ones, so translating a "helpful hint" box from English to German may result in the text length doubling, and therefore no longer able to fit into the box. A translator or author can see this immediately and revise the style sheet to accommodate the text length.
Support for Existing TMS and Authoring Tools
The functionality enabled by integrating authoring with the TMS is powerful. At the same time, documentation professionals and localization experts require the ability to take advantage of the authoring tools and TMSs used to produce their existing localized content. MadCap addresses this at both the authoring and translation levels.
On the authoring side, the Flare and Blaze authoring tools that work with MadCap Lingo can import a range of document types to create the source content. Both can bring in documents from products such as Microsoft Word and Adobe FrameMaker. Following translation, these products provide single-source delivery to multiple formats online and off, including the Internet, intranets, CDs, and print. Print formats supported include the Microsoft XML Paper Specification (XPS) format, Adobe PDF, Adobe FrameMaker, and Microsoft Word. Additionally, Flare supports a number of online content input and output formats.
On the localization front, MadCap Lingo is designed to work with other TMSs. Consequently, localization consultants or in-house translation departments can use their existing TMS with MadCap Lingo to translate new or updated projects without having to complete a file transfer. At the same time, documentation teams that outsource their localization can simply send over a ZIP folder containing the entire project, which remains a cohesive whole maintaining all file relationships.
Document managers also can use MadCap Lingo for quick in-house translation of the last-minute changes that plague almost every project, without having to send files back to the outside firm. If the translation contractor provides a copy of the translation memory database used when delivering the localized content, the very same database can be used with MadCap Lingo to make those last-minute adjustments.
By integrating authoring with the TMS, the sagas of content lost in translation are becoming tales of the past. Replacing them is the promise of documentation that addresses today's global Internet economy by providing a consistent experience online, in print, and in any language.
MadCap Lingo Snapshot:
- Authoring tool with Lingo Server built-in translation memory system, plus ability to connect with third- party TMSs and translate text using the integrated Google service.
- Ability to create "difference" projects, highlighting changed areas that need translation.
- Shortcut keys for quickly performing translation functions and moving around the interface.
- Side-by-side translation editors to simplify the process of localizing topics, tables of contents, index keywords, concepts, glossaries, variables, and more.
- Fully Unicode enabled with full functionality for translating Eastern European, Western European, and Asian languages.
- File list window to display which files require translation.
- Ability to view and edit multiple documents simultaneously.
- Customizable interface to support users' preferred ways of working.
- Works natively in XML with full support for XML-based content.
- Available for $2,199 per license or on a subscription basis of $649 per year. Support options start at $449 per year.
Michael Hamilton, vice president of product management at MadCap Software, has more than ten years of experience in training, technical communication, multimedia development, and software development. Prior to joining MadCap, he served as a product manager for the award-winning RoboHelp product line, first at eHelp and then Macromedia, working closely with the customer community and guiding ongoing development. He also has held positions at Cymer, National Steel & Shipbuilding, and the US Navy. Hamilton is a featured speaker at industry events, Society for Technical Communication annual conference and WinWriters Online Help conferences, as well as shows throughout Europe and Australia.
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Vice President of Product Management,
MadCap Software
Where did my table of contents go? What happened to my glossary? These questions, and many others about document structure and formatting, still arise all too often as these components get lost in translation.
We have seen important technology advances to facilitate the translation of content. Most notable are the growing use of Unicode to support both single- and double-byte languages and adoption of the Extensible Markup Language (XML), which facilitates the sharing of structured data across different systems. As a result, translating a set of words from one language into one or more others is a fairly predictable experience.
Bringing that predictability to the overall document remains a challenge. At the heart of the matter is the fact that document files need to be transferred into a translation memory system (TMS). A TMS can be programmed to recognize the document formatting. However, when localization experts transfer files into these pre-programmed systems, portions of those files-for example variables and indices-often get corrupted.
Even when the actual file transfer is smooth, the fact that there is a transfer leaves room for error and inefficiency. The challenge can be particularly daunting with topic-based authoring. Consider that some projects may have 12,000 files. The project manager needs to ensure that all 12,000 files get sent over for translation and localization. It is not uncommon to get the translation back, and realize that, for example, an index has not been translated. Now the localization project is delayed as the additional file is translated.
Then, too, if there are changes to an existing document, perhaps to reflect a policy change or product upgrade, it may be that only 112 of the 12,000 files need to be updated and translated. It can take hours for the project manager to identify that small subset of files, and hopefully he or she will catch them all.
Translation Without File Transfers
So many of these challenges would disappear if there was no need to actually transfer the data. This is the approach taken with MadCap Lingo, a fully integrated translation memory system and authoring tool that eliminates the need for file transfers in order to complete translation. As a result, documentation and localization professionals no longer have to risk losing valuable content and formatting. Instead, document components-such as tables of contents, topics, index keywords, concepts, glossaries, and variables-all remain intact throughout the translation and localization process, so there is never a need to recreate them. The XML-based MadCap Lingo is also fully Unicode enabled to support any European or Asian language.
MadCap Lingo is tightly integrated with MadCap Flare, a native-XML authoring product, and MadCap Blaze, a native- XML alternative to Adobe FrameMaker for publishing long print documents, which will be generally available in early 2008. A user simply creates a MadCap Lingo project to access the source content in a Flare or Blaze project via a shared file structure. Working through Lingo's interface, the user accesses and translates the content. Because the content never actually leaves the structure of the original Flare or Blaze project, all the content and formatting are preserved in the translated version. Once a project is translated, it is opened in either Flare or Blaze, which generates the output and facilitates publishing.
Taking the file transfer out of translation simplifies and speeds the localization process in many ways. Because there is no transfer, all files are automatically translated; none are left behind. There also is a clear view of all the files that need to be translated. When a MadCap Lingo project is initiated, it automatically lists all of the files in the documentation project. Because the software automatically tracks what files have and haven't been translated, it will recognize if the project is an update to an earlier one, highlighting the files that have been changed and therefore require translation.
With this in mind, let's revisit the example of a project containing 12,000 content files. By allowing the translation to occur within the original project, all 12,000 files are automatically flagged for localization-as well as any support files, such as a table of contents or a list of variables-providing a complete picture of the project. Moreover, when there is an update that affects only 112 files, it is easy for a documentation or localization expert to immediately identify and then translate just those files rather than having to sift through the entire list. Project managers can ensure that their projects are complete while eliminating hours of unnecessary work.
Similarly, project managers often receive an eleventh- hour change that requires only one or two sentence adjustments. With the integrated translation memory system, a documentation or translation expert can quickly make the updates. If the updates affect variables in the project, those variables will be updated automatically as well, making it possible to meet publishing deadlines even with last-minute edits.
The ability to complete translation within the content project means that document and localization professionals can view content as it will be published with the table of contents, images, screen captures, and more. They also can review the original language version and the translated version side by side for comparison. This facilitates the ability to address formatting issues that arise from the translation.
For example, German text strings tend to be longer than English ones, so translating a "helpful hint" box from English to German may result in the text length doubling, and therefore no longer able to fit into the box. A translator or author can see this immediately and revise the style sheet to accommodate the text length.
Support for Existing TMS and Authoring Tools
The functionality enabled by integrating authoring with the TMS is powerful. At the same time, documentation professionals and localization experts require the ability to take advantage of the authoring tools and TMSs used to produce their existing localized content. MadCap addresses this at both the authoring and translation levels.
On the authoring side, the Flare and Blaze authoring tools that work with MadCap Lingo can import a range of document types to create the source content. Both can bring in documents from products such as Microsoft Word and Adobe FrameMaker. Following translation, these products provide single-source delivery to multiple formats online and off, including the Internet, intranets, CDs, and print. Print formats supported include the Microsoft XML Paper Specification (XPS) format, Adobe PDF, Adobe FrameMaker, and Microsoft Word. Additionally, Flare supports a number of online content input and output formats.
On the localization front, MadCap Lingo is designed to work with other TMSs. Consequently, localization consultants or in-house translation departments can use their existing TMS with MadCap Lingo to translate new or updated projects without having to complete a file transfer. At the same time, documentation teams that outsource their localization can simply send over a ZIP folder containing the entire project, which remains a cohesive whole maintaining all file relationships.
Document managers also can use MadCap Lingo for quick in-house translation of the last-minute changes that plague almost every project, without having to send files back to the outside firm. If the translation contractor provides a copy of the translation memory database used when delivering the localized content, the very same database can be used with MadCap Lingo to make those last-minute adjustments.
By integrating authoring with the TMS, the sagas of content lost in translation are becoming tales of the past. Replacing them is the promise of documentation that addresses today's global Internet economy by providing a consistent experience online, in print, and in any language.
MadCap Lingo Snapshot:
- Authoring tool with Lingo Server built-in translation memory system, plus ability to connect with third- party TMSs and translate text using the integrated Google service.
- Ability to create "difference" projects, highlighting changed areas that need translation.
- Shortcut keys for quickly performing translation functions and moving around the interface.
- Side-by-side translation editors to simplify the process of localizing topics, tables of contents, index keywords, concepts, glossaries, variables, and more.
- Fully Unicode enabled with full functionality for translating Eastern European, Western European, and Asian languages.
- File list window to display which files require translation.
- Ability to view and edit multiple documents simultaneously.
- Customizable interface to support users' preferred ways of working.
- Works natively in XML with full support for XML-based content.
- Available for $2,199 per license or on a subscription basis of $649 per year. Support options start at $449 per year.
Michael Hamilton, vice president of product management at MadCap Software, has more than ten years of experience in training, technical communication, multimedia development, and software development. Prior to joining MadCap, he served as a product manager for the award-winning RoboHelp product line, first at eHelp and then Macromedia, working closely with the customer community and guiding ongoing development. He also has held positions at Cymer, National Steel & Shipbuilding, and the US Navy. Hamilton is a featured speaker at industry events, Society for Technical Communication annual conference and WinWriters Online Help conferences, as well as shows throughout Europe and Australia.
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Saturday, May 30, 2009
GMS Spotlight. Staying ahead of the curve
By Eric Richard,
VP, Engineering,
Idiom Technologies, Inc.,
Waltham, Massachusetts, U.S.A.
www.idiominc.com
Working in the translation and localization industry is like constantly working in a pressure cooker. Customers want to get more content translated into more languages with higher quality on faster schedules. And, while the volume of content is scaling up, the costs of translating that content cannot scale up at the same rates.
What makes this problem even more challenging is that this isn’t a short term issue; the amount of content that is going to be translated is going to increase again next year and the year after that and the year after that, for the foreseeable future.
Because of this, translation providers are constantly under pressure to find ways of eking that next round of efficiency out of their processes and cost out of their suppliers to meet the never-ending demands for more, more, more.
The first year a customer asks for a rate cut, it might be possible to squeeze your suppliers to get a better rate from them. But, you can only go back to that well so often before there is nothing left to squeeze.
The next year, you might be able to squeeze some efficiency out of your internal operations. Maybe you can cut a corner here or there to stay ahead of the curve. But, again, there are only so many corners to cut before you are really hurting your ability to deliver quality results.
So, what happens when you run out of corners to cut and low-hanging fruit to pick? How do you deal with the never-ending demands to do more for less? How can you get a non-linear improvement in your efficiencies to help get ahead of the curve?
THE ANSWER IS TECHNOLOGY.
In the 80’s, the technology solution of choice was translation memory (TM). By deploying TM solutions, translators could reuse their previous work and could suddenly process a higher volume of work than before.
Over the past years, translation memory has spread throughout the entire localization supply chain. Translators and LSP’s now use client-side TM in their translation workbenches to improve their efficiencies. And more and more enterprises are realizing that if they own their own TM, they can cut down on their costs and increase the quality and consistency in their translations.
The great news in all of this is that efficiency across the board has increased.
The tough part is that most of the low-hanging fruit in terms of gaining efficiencies may already be behind some early adopter companies. The reason? TM-based solutions are becoming more and more ubiquitous throughout the translation and localization supply chain. That said, however, there are still many companies out there who are ready to drive even more efficiency from the supply chain and, in some cases, start looking for ways to increase top line revenue opportunities.
Once early leaders recognized the value of TM, the search was on for the next big technology solution that could help them stay ahead of the curve. And the solution came in the form of applying workflow to the localization process; by automating previously manual steps, companies could achieve major increases in productivity and quality. Steps previously performed by a human could be performed by machines, reducing the likelihood of errors and freeing up those people to work on the hard problems that computers can’t solve.
Companies who have deployed workflow solutions into their localization processes regularly see immediate improvements. This rarely means reducing staff. Instead, it often means pushing through more content into more languages faster than before with the same staff.
For many organizations that have not yet deployed workflow solutions, this is a great opportunity to improve their efficiencies. Like TM, however, workflow has already crossed the chasm and is moving into the mainstream. Large localization organizations have already deployed workflow solutions and many have even gone through second round refinements to their systems to get most of the big wins already.
For those customers who have already deployed a workflow solution, the real question is "What’s next?" What is the next generation solution that is going to help them deal with the increases in content and keep their advantage in the market?
It is my belief that the next big wave is going to come by combining together the previous two solutions – translation memory and workflow – with another emerging technology: machine translation (MT).
Creating an integrated solution that provides the benefits of both translation memory and machine translation in the context of a workflow solution will provide companies with the ability to make headway into the content stack and start translating more and more content that was previously not even considered for translation.
There are many models in which these technologies can be mixed together.
The simplest, and least disruptive, model is to flow machine translation results into the exact same process that is used today. The result is a process that has been dubbed "machine assisted human translation". The process starts just as it would today with the content being leveraged against a translation memory and resulting in a variety of different types of matches (exact, fuzzy, etc.). But, before providing these results to the translator, this new process takes the most expensive segments – those that do not have a suitable fuzzy match from TM – and runs those segments through machine translation. The end result is that there is never a segment that needs to be translated from scratch; the translator will always have content to start from.
Obviously the devil is in the details here, and the real success of this model will be tied directly to the quality of the results from machine translation. If the machine translation engine results can provide a good starting point for translation, this approach has the ability to increase the productivity of translators.
On the flip side, the most radical model would be to combine machine translation and translation memory together but without any human translator or reviewer involved. The key to this approach is to take a serious look at an issue that is traditionally treated as sacrosanct: translation quality.
"It is my belief that the next big wave is going to come by combining together the previous two solutions-translation memory and workflow-with another emerging technology: machine translation"
In traditional translation processes, quality is non-negotiable. It is simply a non-starter to talk about translating your website, product documentation, software UI, or marketing collateral in anything other than a high quality process.
However, does this same requirement hold true of all of the content that you want to translate? Are there specific types of content for which the quality level is slightly less critical?
Specifically, are there types of content you would not normally translate, but for which the value of having a usable translation is more valuable than having no translation? For example, there may be types of content for which time-to-market of a reasonable translation is more important than taking the time to produce a high quality translation.
For content that fits into these categories, you might consider an approach like the one described above to produce what Jaap van der Meer of TAUS calls "fully automatic useful translation (FAUT)."
It is absolutely critical to understand that this is not proposing that we replace humans with machines for translation. Instead, this is looking at how we can use technology to solve a problem that is too expensive to have humans even try to solve today; this is digging into the enormous mass of content that isn’t even considered for translation today because it would be cost prohibitive to do using traditional means.
The best part of combining machine translation and translation memory with workflow is that the workflow can be used to determine which content should use which processes. The traditional content for which high quality is imperative can go down one path while content that has other requirements can go down another path.
"Translation memory and workflow are by no means mainstream at this point"
You might think that this is science fiction or years from reality, but the visionary companies in the localization industry are already deploying solutions just like this to help them deal with their translation problems today. They see this approach as a fundamental part of how they will address the issue of the volume of content that needs to be translated.
This solution is in the midst of crossing the chasm from the early adopters to the mainstream market. While translation memory and workflow are by no means mainstream at this point, some of the early adopters of content globalization and localization technologies are already looking for the next advantage, a way to keep up with steadily increasing demands. Clearly, these companies should strongly consider integrating machine translation into the mix.
ABOUT IDIOM® TECHNOLOGIES, INC.
Idiom® Technologies is the leading independent supplier of SaaS and on-premise software solutions that enable our customers and partners to accelerate the translation and localization process so content rapidly reaches markets worldwide. Unlike other companies serving this market, Idiom offers freedom of choice by embracing relevant industry standards, supporting popular content lifecycle solutions and partnering with the industry’s leading language service providers.
As a result, WorldServer™ GMS solutions are fast becoming an industry standard, allowing customers to expand their international market reach while reducing costs and improving quality. WorldServer is used every day by organizations possessing many of the most recognizable global brands to more efficiently create and manage multilingual websites (e.g., AOL, eBay and Continental), localize software applications (e.g., Adobe, Beckman Coulter and Motorola) and streamline translation and localization of corporate and product documentation (e.g., Autodesk, Cisco and Business Objects).
Idiom is headquartered in Waltham, Massachusetts, with offices throughout North America and in Europe. WorldServer solutions are also available through the company’s Global Partner Network™. For more information, please visit www.idiominc.com.
ABOUT ERIC RICHARD - VP, ENGINEERING, IDIOM TECHNOLOGIES
Eric Richard joined Idiom from Chicago-based SPSS, where he served as Chief Architect. Previously, he wore several hats as co-founder, Vice President of Engineering, and Chief Technology Officer at NetGenesis (acquired by SPSS), where he directed the company's technology development.
In 2001, Eric was a finalist in the Ernst & Young New England Entrepreneur of the Year Awards. He is a graduate of the Massachusetts Institute of Technology.
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
VP, Engineering,
Idiom Technologies, Inc.,
Waltham, Massachusetts, U.S.A.
www.idiominc.com
Working in the translation and localization industry is like constantly working in a pressure cooker. Customers want to get more content translated into more languages with higher quality on faster schedules. And, while the volume of content is scaling up, the costs of translating that content cannot scale up at the same rates.
What makes this problem even more challenging is that this isn’t a short term issue; the amount of content that is going to be translated is going to increase again next year and the year after that and the year after that, for the foreseeable future.
Because of this, translation providers are constantly under pressure to find ways of eking that next round of efficiency out of their processes and cost out of their suppliers to meet the never-ending demands for more, more, more.
The first year a customer asks for a rate cut, it might be possible to squeeze your suppliers to get a better rate from them. But, you can only go back to that well so often before there is nothing left to squeeze.
The next year, you might be able to squeeze some efficiency out of your internal operations. Maybe you can cut a corner here or there to stay ahead of the curve. But, again, there are only so many corners to cut before you are really hurting your ability to deliver quality results.
So, what happens when you run out of corners to cut and low-hanging fruit to pick? How do you deal with the never-ending demands to do more for less? How can you get a non-linear improvement in your efficiencies to help get ahead of the curve?
THE ANSWER IS TECHNOLOGY.
In the 80’s, the technology solution of choice was translation memory (TM). By deploying TM solutions, translators could reuse their previous work and could suddenly process a higher volume of work than before.
Over the past years, translation memory has spread throughout the entire localization supply chain. Translators and LSP’s now use client-side TM in their translation workbenches to improve their efficiencies. And more and more enterprises are realizing that if they own their own TM, they can cut down on their costs and increase the quality and consistency in their translations.
The great news in all of this is that efficiency across the board has increased.
The tough part is that most of the low-hanging fruit in terms of gaining efficiencies may already be behind some early adopter companies. The reason? TM-based solutions are becoming more and more ubiquitous throughout the translation and localization supply chain. That said, however, there are still many companies out there who are ready to drive even more efficiency from the supply chain and, in some cases, start looking for ways to increase top line revenue opportunities.
Once early leaders recognized the value of TM, the search was on for the next big technology solution that could help them stay ahead of the curve. And the solution came in the form of applying workflow to the localization process; by automating previously manual steps, companies could achieve major increases in productivity and quality. Steps previously performed by a human could be performed by machines, reducing the likelihood of errors and freeing up those people to work on the hard problems that computers can’t solve.
Companies who have deployed workflow solutions into their localization processes regularly see immediate improvements. This rarely means reducing staff. Instead, it often means pushing through more content into more languages faster than before with the same staff.
For many organizations that have not yet deployed workflow solutions, this is a great opportunity to improve their efficiencies. Like TM, however, workflow has already crossed the chasm and is moving into the mainstream. Large localization organizations have already deployed workflow solutions and many have even gone through second round refinements to their systems to get most of the big wins already.
For those customers who have already deployed a workflow solution, the real question is "What’s next?" What is the next generation solution that is going to help them deal with the increases in content and keep their advantage in the market?
It is my belief that the next big wave is going to come by combining together the previous two solutions – translation memory and workflow – with another emerging technology: machine translation (MT).
Creating an integrated solution that provides the benefits of both translation memory and machine translation in the context of a workflow solution will provide companies with the ability to make headway into the content stack and start translating more and more content that was previously not even considered for translation.
There are many models in which these technologies can be mixed together.
The simplest, and least disruptive, model is to flow machine translation results into the exact same process that is used today. The result is a process that has been dubbed "machine assisted human translation". The process starts just as it would today with the content being leveraged against a translation memory and resulting in a variety of different types of matches (exact, fuzzy, etc.). But, before providing these results to the translator, this new process takes the most expensive segments – those that do not have a suitable fuzzy match from TM – and runs those segments through machine translation. The end result is that there is never a segment that needs to be translated from scratch; the translator will always have content to start from.
Obviously the devil is in the details here, and the real success of this model will be tied directly to the quality of the results from machine translation. If the machine translation engine results can provide a good starting point for translation, this approach has the ability to increase the productivity of translators.
On the flip side, the most radical model would be to combine machine translation and translation memory together but without any human translator or reviewer involved. The key to this approach is to take a serious look at an issue that is traditionally treated as sacrosanct: translation quality.
"It is my belief that the next big wave is going to come by combining together the previous two solutions-translation memory and workflow-with another emerging technology: machine translation"
In traditional translation processes, quality is non-negotiable. It is simply a non-starter to talk about translating your website, product documentation, software UI, or marketing collateral in anything other than a high quality process.
However, does this same requirement hold true of all of the content that you want to translate? Are there specific types of content for which the quality level is slightly less critical?
Specifically, are there types of content you would not normally translate, but for which the value of having a usable translation is more valuable than having no translation? For example, there may be types of content for which time-to-market of a reasonable translation is more important than taking the time to produce a high quality translation.
For content that fits into these categories, you might consider an approach like the one described above to produce what Jaap van der Meer of TAUS calls "fully automatic useful translation (FAUT)."
It is absolutely critical to understand that this is not proposing that we replace humans with machines for translation. Instead, this is looking at how we can use technology to solve a problem that is too expensive to have humans even try to solve today; this is digging into the enormous mass of content that isn’t even considered for translation today because it would be cost prohibitive to do using traditional means.
The best part of combining machine translation and translation memory with workflow is that the workflow can be used to determine which content should use which processes. The traditional content for which high quality is imperative can go down one path while content that has other requirements can go down another path.
"Translation memory and workflow are by no means mainstream at this point"
You might think that this is science fiction or years from reality, but the visionary companies in the localization industry are already deploying solutions just like this to help them deal with their translation problems today. They see this approach as a fundamental part of how they will address the issue of the volume of content that needs to be translated.
This solution is in the midst of crossing the chasm from the early adopters to the mainstream market. While translation memory and workflow are by no means mainstream at this point, some of the early adopters of content globalization and localization technologies are already looking for the next advantage, a way to keep up with steadily increasing demands. Clearly, these companies should strongly consider integrating machine translation into the mix.
ABOUT IDIOM® TECHNOLOGIES, INC.
Idiom® Technologies is the leading independent supplier of SaaS and on-premise software solutions that enable our customers and partners to accelerate the translation and localization process so content rapidly reaches markets worldwide. Unlike other companies serving this market, Idiom offers freedom of choice by embracing relevant industry standards, supporting popular content lifecycle solutions and partnering with the industry’s leading language service providers.
As a result, WorldServer™ GMS solutions are fast becoming an industry standard, allowing customers to expand their international market reach while reducing costs and improving quality. WorldServer is used every day by organizations possessing many of the most recognizable global brands to more efficiently create and manage multilingual websites (e.g., AOL, eBay and Continental), localize software applications (e.g., Adobe, Beckman Coulter and Motorola) and streamline translation and localization of corporate and product documentation (e.g., Autodesk, Cisco and Business Objects).
Idiom is headquartered in Waltham, Massachusetts, with offices throughout North America and in Europe. WorldServer solutions are also available through the company’s Global Partner Network™. For more information, please visit www.idiominc.com.
ABOUT ERIC RICHARD - VP, ENGINEERING, IDIOM TECHNOLOGIES
Eric Richard joined Idiom from Chicago-based SPSS, where he served as Chief Architect. Previously, he wore several hats as co-founder, Vice President of Engineering, and Chief Technology Officer at NetGenesis (acquired by SPSS), where he directed the company's technology development.
In 2001, Eric was a finalist in the Ernst & Young New England Entrepreneur of the Year Awards. He is a graduate of the Massachusetts Institute of Technology.
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Wednesday, May 27, 2009
Translations.com – Alchemy Merger Story
By Tony O’Dowd,
CEO and President - Alchemy Software Development
By Phil Shawe,
Co-founder of TransPerfect,
President and CEO of Translations.com
By Keith Becoski, ClientSide News
www.translations.com
CSN: Tony, I saw it mentioned that the purchase process for Alchemy was a competitive situation and that Translations.com was the high bidder. Was there anything else driving the Board’s decision besides maximizing their investment?
TONY: There were a number of factors that drove this decision from our side. For starters, Translations.com is one of a few localization service providers that invest heavily in technology solutions. It was also important to us that we brought something complementary to the table. While Alchemy is a market leader in delivering next-generation TM technology to over 80% of the world’s leading technology companies, Translations.com boasts one of the most widely-adopted workfow platforms in GlobalLink. Since there’s little cross-over in functionality, integrating these two technologies will be rapid from a development perspective, yet powerful for our combined clients. Lastly, Translations.com’s track record of executing successful industry mergers, retaining virtually 100% of staff and clients, and supporting incoming entrepreneurs as they continue to operate their divisions autonomously, also helped us to solidify our decision to merge.
CSN: Phil, what was it about Alchemy that made Translations.com stretch a bit fnancial-ly to make this merger a reality?
PHIL: First and foremost, our mergers are about the people. With Tony, co-founder Enda McDonnell, and the rest of the Alchemy team, we saw a talented group of localization technology veterans who shared our focus on innovation, growth, and client satisfaction. Beyond the wealth of technology talent, Alchemy’s proven and proftable business model is unique among the localization industry’s technology providers. While Alchemy’s leadership in the Visual Localization Tool market is well-established, it gave us extra comfort that we’ve relied on Alchemy technology internally for over five years and have first-hand experience with how effectively CATALYST streamlines the localization process. Lastly, it’s not only Alchemy’s past achievements that impressed us, but also its prospects for the future. We’re very excited to be building on Alchemy’s success and investing in future Alchemy software product offerings.
CSN: Tony, you’ve stated that you intend to stay on with the business post-close. As a shareholder of Alchemy, who has now seen a return from that investment, why stay aboard?
TONY: I’m way too young to think about simply hanging up my hat. What would I do? So the motivation for me in doing this merger was more about opportunity than it was about exiting and doing something else. While I may not have always enjoyed all of the administrative tasks associated with running a company, I have been in the localization industry for 22 years and I’ve always enjoyed it immensely. So for me, the decision to stay on and to be part of driving the growth and development of one of the world’s premier players in this industry is an easy one. And as Phil said, it’s all about the people. My due diligence about the people I’d be working with, as well as the spirit of the merger discussions themselves, led me to believe that this is an interesting and talented group of people for me to join up with.
CSN: And why do you feel this move is right for Alchemy clients?
TONY: Again, Translations.com and Alchemy can combine our R&D spend and deliver more innovative technologies for our clients. Translations.com is a proftable, private company with a very healthy Balance Sheet. In other words, our clients can be confdent that when they are making an investment in technology, they are doing so with a partner who has consistently been fnancially stable. Not motivated by meeting quarterly numbers for the public markets, Translations.com has the advantage of being long-term focused and, as part of our transaction, has pledged long-term investment in Alchemy R&D. Additionally, the combination of our technology with the GlobalLink GMS product suite will enable our clients to achieve greater levels of effciency and scalability in their localization processes. I also believe Translations. com’s post-merger history of retaining employees, management, and clients also makes this the right move for our clients.
CSN: OK, but you’ve failed to touch on the issue on everyone’s mind, what about the loss of independence?
TONY: Our clients value innovation more than independence. Alchemy will operate as an independent division within Translations.com and will continue to develop, distribute, and support our own products. Additionally, the senior management team, such as me and Enda McDonnell, will remain in our existing roles, continuing to exercise our leadership and vision over Alchemy CATALYST and Alchemy Language Exchange. Unlike recent localization industry acquisitions which resulted in large-scale layoffs, we shall be investing in and expanding the development efforts at Alchemy and launching new and exciting technologies later in the year.
CSN: Generally, though, the technology in this industry does seem to be getting gobbled up by the service providers. Who benefts from this?
TONY: Speaking about the Translations.com/Achemy deal, our clients are the ultimate benefciaries of this merger. Technology is playing an increasingly important role in the optimization and effciency of our clients’ localization processes. Even small and medium sized companies see growth opportunities in overseas markets. To take advantage of these growth opportunities they need to localize quickly, cost-effectively, and with high quality. Technology will drive these effciencies making localization more accessible to a wider range of companies and enterprises.
Combining these technology advantages with a full service offering will suit some of our clients. However, we are mindful of the fact that choice is important to many of our clients and that is why Alchemy will remain a fully independent division within Translations.com and our tools will continue to be service provider agnostic.
Because we don’t have overlapping technology, our clients do not need to be concerned about which product lines will be supported in the future, and which will be killed off. Stability, security and a defned roadmap for future development for our combined software offerings will also work to the beneft of our clients.
CSN: What do the language service providers need to know about this and what do the end clients need to know?
TONY: Probably both groups need to know the same things. Alchemy has developed CATALYST into the optimization tool of choice for the localization process, and this development has served all who manage localization, whether they are an LSP or an end client. So what all localization stakeholders need to know is that Alchemy and Translations.com intend to work together collectively to continue investing in and driving the evolution of CATALYST and Alchemy Language Exchange, which are not captive and are used in conjunction with other LSPs’ services.
PHIL: We also feel that increased competition in the localization technology sector will drive more innovation, and this transaction is likely to result in increased competition.
CSN: Phil, how will this merger differ from the SDL/ Idiom merger which is leaving a perceived lack of independence and choice?
PHIL: Translations.com has a reputation of merging with companies and retaining virtually 100% of the entrepreneurial skills and enthusiasm of the existing teams and management. This has proven to be a very successful strategy. While I don’t know that it’s accurate to say that this approach to M&A is unique, it certainly does differ from the approach of SDL, the obvious comparison here given their recent and past technology acquisitions. In fairness, they are a public company with a requirement to operate and to consolidate acquired businesses in a way that makes sense to investors. As a private company, Translations.com is free to take a more long-term approach, and we see the value in supporting entrepreneurs and their businesses.
Furthermore, the Alchemy/Translations.com merger differs from – again the natural, but not entirely analogous, comparison – SDL/Idiom, in that this merger has not manifested a direct contradiction of a promise. Many clients and partners asked Idiom directly if they intended to sell the company to a service provider. Idiom sold their solutions on a promise to remain independent. Alchemy made no such promise because, without the same access to confdential partner information that is inherent in the way WorldServer functions, there was never any reason for CATALYST to be sold with a pledge of independence.
CSN: How has the recent SDL/Idiom merger affected Translations.com?
PHIL: As far as companies performing services through an Idiom platform, Translations.com is probably among the largest in the world. However, you never saw a public partnership announced. One reason is that Idiom competes directly with our GlobalLink suite of products. However, another reason was that we felt we couldn’t predict the future actions of venture capitalists that controlled Idiom, and envisioned the potential of them selling out to a competing LSP.
Now, of course we’re concerned that SDL has, in effect, purchased our pricing information and other knowledge we once considered confdential, because it is stored on Idiom servers. As there is nothing legally preventing SDL from making use of this information to compete for service revenues, we expect them to cross-sell aggressively into those accounts.
When you step back and think about it, Idiom was losing over $5 million a year and SDL has competing and overlapping technology, so why buy the company for over $20 million? It may be that the real value in the deal for SDL shareholders is simply the future ability to cross-sell more services through 1) the built-in dependency and high-switching costs associated with being a technology vendor and 2) the access to once-confdential proprietary competitor information.
Note that there is nothing “wrong” with what SDL is doing by pursuing this strategy. Quite the contrary, having spent $20+ million of their shareholders’ money, they now have a fduciary obligation to maximize that value, and make the most of their new-found client relationships and competitor information.
After the Idiom deal, we feel how we’ve always felt about SDL: their technology is primarily about three things; a Trojan Horse with which to establish diffcult-to-break relationships to better sell services, an image necessary to fetch them a higher valuation in the public markets (i.e. a software vs. services valuation), and a vehicle that they’ve quite cleverly used to get competitors to help fnance their R&D and operations.
In summary, we respected SDL as a tough competitor before they bought Idiom, and we expect them to continue to be a tough competitor. As always, we look forward to the challenge of going head-to-head with them in the marketplace, on both services and technology.
CSN: So Tony, what’s the “real story” in terms of value to the market place? How and why will this be a positive alliance for the industry?
TONY: The ‘real story’ is about offering choice. Our clients want to manage their localization content more effciently across multiple localization service providers. A solution that is vendor agnostic, using web based architecture and built on open standards that offers enterprise level scalability is key to their continued growth. This is where Translations.com and Alchemy have invested heavily over the past few years.
CSN: Phil, what does this merger mean in terms of your competitive position?
PHIL: Over the past several years, Translations.com has been fortunate enough to be one of the fastest growing players in the localization industry. Enterprise localization clients are increasingly aware of the value we bring to the table. With the addition of a market leader such as Alchemy, we expect to see this trend continue.
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
CEO and President - Alchemy Software Development
By Phil Shawe,
Co-founder of TransPerfect,
President and CEO of Translations.com
By Keith Becoski, ClientSide News
www.translations.com
CSN: Tony, I saw it mentioned that the purchase process for Alchemy was a competitive situation and that Translations.com was the high bidder. Was there anything else driving the Board’s decision besides maximizing their investment?
TONY: There were a number of factors that drove this decision from our side. For starters, Translations.com is one of a few localization service providers that invest heavily in technology solutions. It was also important to us that we brought something complementary to the table. While Alchemy is a market leader in delivering next-generation TM technology to over 80% of the world’s leading technology companies, Translations.com boasts one of the most widely-adopted workfow platforms in GlobalLink. Since there’s little cross-over in functionality, integrating these two technologies will be rapid from a development perspective, yet powerful for our combined clients. Lastly, Translations.com’s track record of executing successful industry mergers, retaining virtually 100% of staff and clients, and supporting incoming entrepreneurs as they continue to operate their divisions autonomously, also helped us to solidify our decision to merge.
CSN: Phil, what was it about Alchemy that made Translations.com stretch a bit fnancial-ly to make this merger a reality?
PHIL: First and foremost, our mergers are about the people. With Tony, co-founder Enda McDonnell, and the rest of the Alchemy team, we saw a talented group of localization technology veterans who shared our focus on innovation, growth, and client satisfaction. Beyond the wealth of technology talent, Alchemy’s proven and proftable business model is unique among the localization industry’s technology providers. While Alchemy’s leadership in the Visual Localization Tool market is well-established, it gave us extra comfort that we’ve relied on Alchemy technology internally for over five years and have first-hand experience with how effectively CATALYST streamlines the localization process. Lastly, it’s not only Alchemy’s past achievements that impressed us, but also its prospects for the future. We’re very excited to be building on Alchemy’s success and investing in future Alchemy software product offerings.
CSN: Tony, you’ve stated that you intend to stay on with the business post-close. As a shareholder of Alchemy, who has now seen a return from that investment, why stay aboard?
TONY: I’m way too young to think about simply hanging up my hat. What would I do? So the motivation for me in doing this merger was more about opportunity than it was about exiting and doing something else. While I may not have always enjoyed all of the administrative tasks associated with running a company, I have been in the localization industry for 22 years and I’ve always enjoyed it immensely. So for me, the decision to stay on and to be part of driving the growth and development of one of the world’s premier players in this industry is an easy one. And as Phil said, it’s all about the people. My due diligence about the people I’d be working with, as well as the spirit of the merger discussions themselves, led me to believe that this is an interesting and talented group of people for me to join up with.
CSN: And why do you feel this move is right for Alchemy clients?
TONY: Again, Translations.com and Alchemy can combine our R&D spend and deliver more innovative technologies for our clients. Translations.com is a proftable, private company with a very healthy Balance Sheet. In other words, our clients can be confdent that when they are making an investment in technology, they are doing so with a partner who has consistently been fnancially stable. Not motivated by meeting quarterly numbers for the public markets, Translations.com has the advantage of being long-term focused and, as part of our transaction, has pledged long-term investment in Alchemy R&D. Additionally, the combination of our technology with the GlobalLink GMS product suite will enable our clients to achieve greater levels of effciency and scalability in their localization processes. I also believe Translations. com’s post-merger history of retaining employees, management, and clients also makes this the right move for our clients.
CSN: OK, but you’ve failed to touch on the issue on everyone’s mind, what about the loss of independence?
TONY: Our clients value innovation more than independence. Alchemy will operate as an independent division within Translations.com and will continue to develop, distribute, and support our own products. Additionally, the senior management team, such as me and Enda McDonnell, will remain in our existing roles, continuing to exercise our leadership and vision over Alchemy CATALYST and Alchemy Language Exchange. Unlike recent localization industry acquisitions which resulted in large-scale layoffs, we shall be investing in and expanding the development efforts at Alchemy and launching new and exciting technologies later in the year.
CSN: Generally, though, the technology in this industry does seem to be getting gobbled up by the service providers. Who benefts from this?
TONY: Speaking about the Translations.com/Achemy deal, our clients are the ultimate benefciaries of this merger. Technology is playing an increasingly important role in the optimization and effciency of our clients’ localization processes. Even small and medium sized companies see growth opportunities in overseas markets. To take advantage of these growth opportunities they need to localize quickly, cost-effectively, and with high quality. Technology will drive these effciencies making localization more accessible to a wider range of companies and enterprises.
Combining these technology advantages with a full service offering will suit some of our clients. However, we are mindful of the fact that choice is important to many of our clients and that is why Alchemy will remain a fully independent division within Translations.com and our tools will continue to be service provider agnostic.
Because we don’t have overlapping technology, our clients do not need to be concerned about which product lines will be supported in the future, and which will be killed off. Stability, security and a defned roadmap for future development for our combined software offerings will also work to the beneft of our clients.
CSN: What do the language service providers need to know about this and what do the end clients need to know?
TONY: Probably both groups need to know the same things. Alchemy has developed CATALYST into the optimization tool of choice for the localization process, and this development has served all who manage localization, whether they are an LSP or an end client. So what all localization stakeholders need to know is that Alchemy and Translations.com intend to work together collectively to continue investing in and driving the evolution of CATALYST and Alchemy Language Exchange, which are not captive and are used in conjunction with other LSPs’ services.
PHIL: We also feel that increased competition in the localization technology sector will drive more innovation, and this transaction is likely to result in increased competition.
CSN: Phil, how will this merger differ from the SDL/ Idiom merger which is leaving a perceived lack of independence and choice?
PHIL: Translations.com has a reputation of merging with companies and retaining virtually 100% of the entrepreneurial skills and enthusiasm of the existing teams and management. This has proven to be a very successful strategy. While I don’t know that it’s accurate to say that this approach to M&A is unique, it certainly does differ from the approach of SDL, the obvious comparison here given their recent and past technology acquisitions. In fairness, they are a public company with a requirement to operate and to consolidate acquired businesses in a way that makes sense to investors. As a private company, Translations.com is free to take a more long-term approach, and we see the value in supporting entrepreneurs and their businesses.
Furthermore, the Alchemy/Translations.com merger differs from – again the natural, but not entirely analogous, comparison – SDL/Idiom, in that this merger has not manifested a direct contradiction of a promise. Many clients and partners asked Idiom directly if they intended to sell the company to a service provider. Idiom sold their solutions on a promise to remain independent. Alchemy made no such promise because, without the same access to confdential partner information that is inherent in the way WorldServer functions, there was never any reason for CATALYST to be sold with a pledge of independence.
CSN: How has the recent SDL/Idiom merger affected Translations.com?
PHIL: As far as companies performing services through an Idiom platform, Translations.com is probably among the largest in the world. However, you never saw a public partnership announced. One reason is that Idiom competes directly with our GlobalLink suite of products. However, another reason was that we felt we couldn’t predict the future actions of venture capitalists that controlled Idiom, and envisioned the potential of them selling out to a competing LSP.
Now, of course we’re concerned that SDL has, in effect, purchased our pricing information and other knowledge we once considered confdential, because it is stored on Idiom servers. As there is nothing legally preventing SDL from making use of this information to compete for service revenues, we expect them to cross-sell aggressively into those accounts.
When you step back and think about it, Idiom was losing over $5 million a year and SDL has competing and overlapping technology, so why buy the company for over $20 million? It may be that the real value in the deal for SDL shareholders is simply the future ability to cross-sell more services through 1) the built-in dependency and high-switching costs associated with being a technology vendor and 2) the access to once-confdential proprietary competitor information.
Note that there is nothing “wrong” with what SDL is doing by pursuing this strategy. Quite the contrary, having spent $20+ million of their shareholders’ money, they now have a fduciary obligation to maximize that value, and make the most of their new-found client relationships and competitor information.
After the Idiom deal, we feel how we’ve always felt about SDL: their technology is primarily about three things; a Trojan Horse with which to establish diffcult-to-break relationships to better sell services, an image necessary to fetch them a higher valuation in the public markets (i.e. a software vs. services valuation), and a vehicle that they’ve quite cleverly used to get competitors to help fnance their R&D and operations.
In summary, we respected SDL as a tough competitor before they bought Idiom, and we expect them to continue to be a tough competitor. As always, we look forward to the challenge of going head-to-head with them in the marketplace, on both services and technology.
CSN: So Tony, what’s the “real story” in terms of value to the market place? How and why will this be a positive alliance for the industry?
TONY: The ‘real story’ is about offering choice. Our clients want to manage their localization content more effciently across multiple localization service providers. A solution that is vendor agnostic, using web based architecture and built on open standards that offers enterprise level scalability is key to their continued growth. This is where Translations.com and Alchemy have invested heavily over the past few years.
CSN: Phil, what does this merger mean in terms of your competitive position?
PHIL: Over the past several years, Translations.com has been fortunate enough to be one of the fastest growing players in the localization industry. Enterprise localization clients are increasingly aware of the value we bring to the table. With the addition of a market leader such as Alchemy, we expect to see this trend continue.
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Tuesday, May 26, 2009
The evolution of localization tools
By Michael Trent,
Lingobit Technologies
Some time ago, only few people knew about software localization tools, but now such tools have become an essential part of software development process. This article tells about transformation of localization software from simple tools developed in-house to powerful software suites that support multiple platforms and languages, provide advanced functionality and make software localization affordable to any company.
First steps
Localization revolves around combining language and technology to produce a product that can cross language and cultural barriers. Initially, software companies considered localization as an afterthought. When the original application was released in English and developers went on vacation, translators were put to work to produce a German, French, Chinese, etc. version. Initially, translators just changed text strings directly in source code, which was time-consuming and an error-prone process. It required translators to understand programming language and review huge amount of source code to translate few lines of text.
Locating translatable text embedded in software source code was very difficult and source code localization made code updates and version management a nightmare. As a result, localization at that time used to be very expensive in both time and money. It often produced unsatisfactory results and introduced new bugs in software.
First localization tools that appeared on the market were no more than simple utilities to simplify some parts of this process by locating text strings and managing code updates. They were limited in functionality and were mostly developed for in-house use and, in most cases, for some particular product. However, for all these difficulties, even those first localization tools allowed developers to reduce localization costs significantly.
The shift of computer software use away from centralized corporate and academic environments to usersT desks called for a shift in products features and functionality. Desktop computer users needed software that would enable them to do their work more efficiently and software also had to be in their local language. Releasing software in multiple languages became necessary not only for big software developers such as Microsoft or IBM, but also for smaller software companies. This triggered development of the first commercial localization tools.
First commercial localization tools used binary localization of executable files, rather than localization of the source code because this approach separated localization from software development. Translators were no longer required to know programming languages and many technical complexities were hidden from translators. Binary localization led to a considerable reduction in number of errors caused by localization and it made possible to easily sync translations when the software updates were released.
Localization vs. CAT tools
Companies that developed Computer Aided Translation (CAT) tools also tried to enter software localization market but most of them failed because they are designed for a different purpose. In CAT systems, output is a translated text, whereas in case of localization tools it is only an intermediary stage. The objective of localization is to adapt the product for local markets. This means not only translation of text, but also resizing dialogs, changing images and multiple other things. To do so, localization engineers get a copy of the software, extract translatable text from multiple files, do the translation, merge the translated files with the software build and produce localized copies of the application.
One of the major strengths of CAT systems is a translation memory but it is only partially useful in software localization for several reasons. Translation Memory database from one product cannot be reused in other products and, what is more, even in the same application same text in is often translated differently.
Riding the dot-com wave, localization tools evolved and by the end of the 1990s took over and implemented CAT tool functionality. Currently, traditional CAT tools no longer play a significant role in the localization industry.
Product-centric localization
Products developed today utilize multiple technologies and combine managed and unmanaged code, web components and even code targeting different operating systems. In large projects, there are hundreds of files that require localization and old tools that use by-file localization and target specific platforms are no longer up to a job. New crop of software localization products add support for folder-based localization, multiple development platforms and unify all localization efforts by supporting translation of help files and online documentation.
Folder-based localization tool
When a project has hundreds of localizable files in different directories, it becomes very difficult to manage without using folder-based localization. Tools that support folder-based localization automatically track new, removed and changed files, synchronize translation between files and keep project structure intact.
When multiple people work on the development of a large application, itTs difficult for localization engineers to track what files with localizable text are added and removed from the project. It used to be time-consuming and error-prone work but tools with support for folder-based localization automate this process by detecting new files, determining whether they contain text for translation and then adding them to the project.
Support for multiple formats
One of the specialties that characterize the localization industry today is support for multiple development platforms. In the past, most applications were developed using only one platform, but over time, products became more complex. Many products today contain both legacy code and new code in different programming languages. WhatTs more, as more products move into the Web, with its multitude of languages support for different platforms, this becomes even more important.
Localization on mobile devices
There are more mobile devices than computers in the world and many products have mobile version. While most people who work on computer have at least basic knowledge of English, majority of mobile phone users do not speak English at all. Support for .NET Compact Edition, Windows CE and Java Mobile Edition is standard in modern localization tools.
Help and documentation
Some software localization products added support for localization of documentation, websites and help. While CAT tools are better suited for translation of large amount of text, localization tools are better at translating text in structured form. WhatTs more, using localization tools for help and documentation allows companies to standardize on one product and lower support cost.
Conclusion
Over a short period, localization tools have gone a long way from simple utilities for in-house localization teams to complex product-centric systems, providing tools for the entire localization process. Technologies such as binary localization and translation memory dramatically increased localization efficiency. WhatTs more, modern localization tools compete in documentation and web content translation space with CAT systems, offering the developer a unified environment for entire software product localization.
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Lingobit Technologies
Some time ago, only few people knew about software localization tools, but now such tools have become an essential part of software development process. This article tells about transformation of localization software from simple tools developed in-house to powerful software suites that support multiple platforms and languages, provide advanced functionality and make software localization affordable to any company.
First steps
Localization revolves around combining language and technology to produce a product that can cross language and cultural barriers. Initially, software companies considered localization as an afterthought. When the original application was released in English and developers went on vacation, translators were put to work to produce a German, French, Chinese, etc. version. Initially, translators just changed text strings directly in source code, which was time-consuming and an error-prone process. It required translators to understand programming language and review huge amount of source code to translate few lines of text.
Locating translatable text embedded in software source code was very difficult and source code localization made code updates and version management a nightmare. As a result, localization at that time used to be very expensive in both time and money. It often produced unsatisfactory results and introduced new bugs in software.
First localization tools that appeared on the market were no more than simple utilities to simplify some parts of this process by locating text strings and managing code updates. They were limited in functionality and were mostly developed for in-house use and, in most cases, for some particular product. However, for all these difficulties, even those first localization tools allowed developers to reduce localization costs significantly.
The shift of computer software use away from centralized corporate and academic environments to usersT desks called for a shift in products features and functionality. Desktop computer users needed software that would enable them to do their work more efficiently and software also had to be in their local language. Releasing software in multiple languages became necessary not only for big software developers such as Microsoft or IBM, but also for smaller software companies. This triggered development of the first commercial localization tools.
First commercial localization tools used binary localization of executable files, rather than localization of the source code because this approach separated localization from software development. Translators were no longer required to know programming languages and many technical complexities were hidden from translators. Binary localization led to a considerable reduction in number of errors caused by localization and it made possible to easily sync translations when the software updates were released.
Localization vs. CAT tools
Companies that developed Computer Aided Translation (CAT) tools also tried to enter software localization market but most of them failed because they are designed for a different purpose. In CAT systems, output is a translated text, whereas in case of localization tools it is only an intermediary stage. The objective of localization is to adapt the product for local markets. This means not only translation of text, but also resizing dialogs, changing images and multiple other things. To do so, localization engineers get a copy of the software, extract translatable text from multiple files, do the translation, merge the translated files with the software build and produce localized copies of the application.
One of the major strengths of CAT systems is a translation memory but it is only partially useful in software localization for several reasons. Translation Memory database from one product cannot be reused in other products and, what is more, even in the same application same text in is often translated differently.
Riding the dot-com wave, localization tools evolved and by the end of the 1990s took over and implemented CAT tool functionality. Currently, traditional CAT tools no longer play a significant role in the localization industry.
Product-centric localization
Products developed today utilize multiple technologies and combine managed and unmanaged code, web components and even code targeting different operating systems. In large projects, there are hundreds of files that require localization and old tools that use by-file localization and target specific platforms are no longer up to a job. New crop of software localization products add support for folder-based localization, multiple development platforms and unify all localization efforts by supporting translation of help files and online documentation.
Folder-based localization tool
When a project has hundreds of localizable files in different directories, it becomes very difficult to manage without using folder-based localization. Tools that support folder-based localization automatically track new, removed and changed files, synchronize translation between files and keep project structure intact.
When multiple people work on the development of a large application, itTs difficult for localization engineers to track what files with localizable text are added and removed from the project. It used to be time-consuming and error-prone work but tools with support for folder-based localization automate this process by detecting new files, determining whether they contain text for translation and then adding them to the project.
Support for multiple formats
One of the specialties that characterize the localization industry today is support for multiple development platforms. In the past, most applications were developed using only one platform, but over time, products became more complex. Many products today contain both legacy code and new code in different programming languages. WhatTs more, as more products move into the Web, with its multitude of languages support for different platforms, this becomes even more important.
Localization on mobile devices
There are more mobile devices than computers in the world and many products have mobile version. While most people who work on computer have at least basic knowledge of English, majority of mobile phone users do not speak English at all. Support for .NET Compact Edition, Windows CE and Java Mobile Edition is standard in modern localization tools.
Help and documentation
Some software localization products added support for localization of documentation, websites and help. While CAT tools are better suited for translation of large amount of text, localization tools are better at translating text in structured form. WhatTs more, using localization tools for help and documentation allows companies to standardize on one product and lower support cost.
Conclusion
Over a short period, localization tools have gone a long way from simple utilities for in-house localization teams to complex product-centric systems, providing tools for the entire localization process. Technologies such as binary localization and translation memory dramatically increased localization efficiency. WhatTs more, modern localization tools compete in documentation and web content translation space with CAT systems, offering the developer a unified environment for entire software product localization.
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Monday, May 25, 2009
Translation Buyers' Views on Technology Independence
By Ben Sargent,
Senior Analyst,
Common Sense Advisory
In late mid-2008, Common Sense Advisory asked buyers of translation services for their views on technology independence among their software and language vendors. Over half the 30-plus respondents hailed from North America; 35 percent were from Europe; the balance were scattered across that amorphous continent known as "Rest of World."
Our first question asked, "How important is it for your technology vendor to be a different company than the firm that provides translation services?" About 60 percent said technology independence was "somewhat important" or "very important."

Source: Common Sense Advisory, Inc.
Stated more bluntly, we were asking buyers what they felt about using technology tied to a specific language services provider (LSP), such as Lionbridge, Sajan, SDL, or Translations.com. Given the high proportion of "very important" responses coupled with zero buyers stating "very unimportant," the balance of opinion among buyers tilts radically toward concern on this topic, even though 39 percent said it was "not important."
Next, we asked buyers if a guarantee of independence from the vendor would influence their purchasing decision. Over 80 percent indicated that it would.
Source: Common Sense Advisory, Inc.
Expect non-service vendors to take advantage of this buying criterion, in both marketing platitudes and in the more hand-to-hand combat of direct selling. However, not all buyers will take such promises at face value. Last year, two notable independent software companies, Alchemy and Idiom, were swallowed by large LSPs (Translations.com and SDL, respectively). When we asked how recent mergers and acquisitions (M&A) had affected their views regarding vendor independence, 60 percent of buyers told us industry consolidation had raised their skepticism about any vendor's ability to remain independent over time.
Other reactions included 25 percent who said they were pushed to explore internal development options; 35 percent who set off to look for new independent vendors; and 45 percent for whom it triggered an exploration of open source solutions. Only 16 percent say the consolidation did not alter their views on vendor independence.

Source: Common Sense Advisory, Inc.
But apparently many companies did not need M&A activities to trigger their interest in open source. When we asked if it was likely their company would use open-source software for translation automation projects, nearly three out of four said they are "somewhat likely" or "very likely" to do so. This receptiveness could bode well for an open-source Global Sight — if Welocalize succeeds in mobilizing a community and eliciting a sense of ownership beyond itself.
Source: Common Sense Advisory, Inc.
Fewer companies are developing their own solutions for translation automation. Half said they were not, 30 percent said they were, and 20 percent claimed to be thinking about it.
Translation Buyers' Views on Technology Independence
Source: Common Sense Advisory, Inc.
So, our survey comes down to two conflicting datapoints:
* Our research on translation management systems (TMS) shows that most high-scoring systems are offered by language service providers, not by independent software vendors (ISVs). Suppliers such as Lionbridge, Sajan, SDL, and Translations.com are not only LSPs, but leading proponents of TMS in the openly available enterprise or captive "house" categories (house systems are available only through service agreements with those LSPs).
* However, buyers unequivocally tell us they worry about vendor independence and that it affects buying decisions.
This cognitive dissonance explains the difficult selling environment that LSPs find themselves in when pushing their proprietary technology approaches. And why unaffiliated software vendors have clay feet when it comes to the question of independence. Across, Beetext, and Kilgray have no financial ties to LSPs — yet. Maybe these new players will be the ones who finally turn the corner and prove that ISVs can survive in this service-oriented marketplace. But over the last decade, LSPs have harvested pretty much every leading software vendor in the space — more than 10 companies in all. Common Sense Advisory anticipates that acquisition by an LSP is still the most likely "exit strategy" for any globalization software vendor (GSV) operating today.
Published - April 2009
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Senior Analyst,
Common Sense Advisory
In late mid-2008, Common Sense Advisory asked buyers of translation services for their views on technology independence among their software and language vendors. Over half the 30-plus respondents hailed from North America; 35 percent were from Europe; the balance were scattered across that amorphous continent known as "Rest of World."
Our first question asked, "How important is it for your technology vendor to be a different company than the firm that provides translation services?" About 60 percent said technology independence was "somewhat important" or "very important."
Source: Common Sense Advisory, Inc.
Stated more bluntly, we were asking buyers what they felt about using technology tied to a specific language services provider (LSP), such as Lionbridge, Sajan, SDL, or Translations.com. Given the high proportion of "very important" responses coupled with zero buyers stating "very unimportant," the balance of opinion among buyers tilts radically toward concern on this topic, even though 39 percent said it was "not important."
Next, we asked buyers if a guarantee of independence from the vendor would influence their purchasing decision. Over 80 percent indicated that it would.
Source: Common Sense Advisory, Inc.
Expect non-service vendors to take advantage of this buying criterion, in both marketing platitudes and in the more hand-to-hand combat of direct selling. However, not all buyers will take such promises at face value. Last year, two notable independent software companies, Alchemy and Idiom, were swallowed by large LSPs (Translations.com and SDL, respectively). When we asked how recent mergers and acquisitions (M&A) had affected their views regarding vendor independence, 60 percent of buyers told us industry consolidation had raised their skepticism about any vendor's ability to remain independent over time.
Other reactions included 25 percent who said they were pushed to explore internal development options; 35 percent who set off to look for new independent vendors; and 45 percent for whom it triggered an exploration of open source solutions. Only 16 percent say the consolidation did not alter their views on vendor independence.
Source: Common Sense Advisory, Inc.
But apparently many companies did not need M&A activities to trigger their interest in open source. When we asked if it was likely their company would use open-source software for translation automation projects, nearly three out of four said they are "somewhat likely" or "very likely" to do so. This receptiveness could bode well for an open-source Global Sight — if Welocalize succeeds in mobilizing a community and eliciting a sense of ownership beyond itself.
Source: Common Sense Advisory, Inc.
Fewer companies are developing their own solutions for translation automation. Half said they were not, 30 percent said they were, and 20 percent claimed to be thinking about it.
Translation Buyers' Views on Technology Independence
Source: Common Sense Advisory, Inc.
So, our survey comes down to two conflicting datapoints:
* Our research on translation management systems (TMS) shows that most high-scoring systems are offered by language service providers, not by independent software vendors (ISVs). Suppliers such as Lionbridge, Sajan, SDL, and Translations.com are not only LSPs, but leading proponents of TMS in the openly available enterprise or captive "house" categories (house systems are available only through service agreements with those LSPs).
* However, buyers unequivocally tell us they worry about vendor independence and that it affects buying decisions.
This cognitive dissonance explains the difficult selling environment that LSPs find themselves in when pushing their proprietary technology approaches. And why unaffiliated software vendors have clay feet when it comes to the question of independence. Across, Beetext, and Kilgray have no financial ties to LSPs — yet. Maybe these new players will be the ones who finally turn the corner and prove that ISVs can survive in this service-oriented marketplace. But over the last decade, LSPs have harvested pretty much every leading software vendor in the space — more than 10 companies in all. Common Sense Advisory anticipates that acquisition by an LSP is still the most likely "exit strategy" for any globalization software vendor (GSV) operating today.
Published - April 2009
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Saturday, May 23, 2009
Where Do Translators Fit into Machine Translation?
By Alex Gross
http://language.home.sprynet.com/
alexilen@sprynet.com
Original and Supplementary Questions
Submitted to the MT Summit III Conference,
Washington, 1991
Here are the original questions for this panel as submitted to the speakers:
1. At the last MT Summit, Martin Kay stated that there should be "greater attention to empirical studies of translation so that computational linguists will have a better idea of what really goes on in translation and develop tools that will be more useful for the end user." Does this mean that there has been insufficient input into MT processes by translators interested in MT? Does it mean that MT developers have failed to study what translating actually entails and how translators go about their task? If either of these is true, then to what extent and why? New answers and insights for the MT profession could arise from hearing what human translators with an interest in the development of MT have to say about these matters. It may well turn out that translators are the very people best qualified to determine what form their tools should take, since they are the end users.
2. Is there a specifically "human" component in the translation process which MT experts have overlooked? Is it reasonable for theoreticians to envision setting up predictable and generic vocabularies of clearly defined terms, or could they be overlooking a deep-seated human tendency towards some degree of ambiguity—indeed, in those many cases where not all the facts are known, an inescapably human reliance on it? Are there any viable MT approaches to duplicate what human translators can provide in such cases, namely the ability to bridge this ambiguity gap and improvise personalized, customized case-specific subtleties of vocabulary, depending on client or purpose? Could this in fact be a major element of the entire translation process? Alternately, are there some more boring "machine-like" aspects of translation where the computer can help the translator, such as style and consistency checking?
3. How can the knowledge of practicing translators best be integrated into current MT research and working systems? Is it to be assumed that they are best employed as prospective end-users working out the bugs in the system, or is there also a place for them during the initial planning phases of such systems? Can they perhaps as users be the primary developers of the system?
4. Many human translators, when told of the quest to have machines take over all aspects of translation, immediately reply that this is impossible and start providing specific instances which they claim a machine system could never handle. Are such reactions merely the final nerve spasms of a doomed class of technicians awaiting superannuation, or are these translators in fact enunciating specific instances of a general law as yet not fully articulated?
Since we now hear claims suggesting that FAHQT is creeping in again through the back door, it seems important to ask whether there has in fact ever been sufficient basic mathematical research, much less algorithmic underpinnings, by the MT Community to determine whether FAHQT, or anything close to it, can be achieved by any combination of electronic stratagems (transfer, AI, neural nets, Markov models, etc.).
Must translators forever stand exposed on the firing line and present their minds and bodies to a broadside of claims that the next round of computer advances will annihilate them as a profession? Is this problem truly solvable in logical terms, or is it in fact an intractable, undecidable, or provably unsolvable question in terms of "Computable Numbers" as set out by Turing, based on the work of Hilbert and Goedel? A reasonable answer to this question could save boards of directors and/or government agencies a great deal of time and money.
SUPPLEMENTAL QUESTIONS:
It was also envisioned that a list of Supplemental Questions would be prepared and distributed not only to the speakers but everyone attending our panel, even though not all of these questions could be raised during the session, so as to deepen our discussion and provide a lasting record of these issues.
FAHQT: Pro and Con
Consider the following observation on FAHQT: "The ideal notion of fully automatic high quality translation (FAHQT) is still lurking behind the machine translation paradigm: it is something that MT projects want to reach." (1) Is this a true or a false observation?
Is FAHQT merely a matter of time and continued research, a direct and inevitable result of a perfectly asymptotic process?
Will FAHQT ever be available on a held-held calculator-sized computer? If not, then why not?
To what extent is the belief in the feasibility of FAHQT a form of religion or perhaps akin to a belief that a perpetual motion device can be invented?
Technical Linguistic Questions
Let us suppose a writer has chosen to use Word C in a source text because s/he did not wish to use Word A or Word B, even though all three are shown as "synonyms." It turns out that all three of these words overlap and semantically interrelate quite differently in the target language. How can MT handle such an instance, fairly frequently found in legal and diplomatic usage?
Virtually all research in both conventional and computational linguistics has proceeded from the premise that language can be represented and mapped as a linear entity and is therefore eminently computable. What if it turns out that language in fact occupies a virtual space as a multi-dimensional construct, including several fractal dimensions, involving all manner of non-linear turbulence, chaos, and Butterfly Effects?
Post-Editors and Puppeteers
Let's assume you saw an ad for an Automatic Electronic Puppeteer that guaranteed to create and produce endless puppet plays in your own living room. There would be no need for a puppeteer to run the puppets and no need for you even to script the plays, though you would have the freedom to intervene in the action and change the plot as you wished. Since the price was acceptable, you ordered this system, but when it arrived, you found that it required endless installation work and calls to the manufacturers to get it working. But even then, you discovered that the number of plays provided was in fact quite limited, your plot change options even more so, and that the movements of the puppets were jerky and unnatural. When you complained, you were referred to fine print in the docs telling you that to make the program work better, you would have to do one of two things: 1) master an extremely complex programming language or 2) hire a specially trained puppeteer to help you out with your special needs and to be on hand during your productions to make the puppets move more naturally. Does this description bear any resemblance to the way MT has functioned and been promoted in recent years?
A Practical Example
Despite many presentations on linguistic, electronic and philosophical aspects of MT at this conference, one side of translation has nonetheless gone unexplored. It has to do with how larger translation projects actually arise and are handled by the profession. The following story shows the world of human translation at close to its worst, and it might be imagined at first glance that MT could easily do a much better job and simply take over in such situations, which are far from atypical in the world of translation. But, as we shall see, such appearances may be deceptive. To our story:
A French electrical firm was recently involved in a hostile take-over bid and law suit with its American counterpart. Large numbers of boxes and drawers full of documents all had to be translated into English by an almost impossible deadline. Supervision of this work was entrusted to a paralegal assistant in the French company's New York law firm. This person had no previous knowledge of translation. The documents ran the gamut from highly technical electrical texts and patents, records of previous law suits, company correspondence, advertisements, product documentation, speeches by the Company's directors, etc.
Almost every French-to-English translator in the NYC area was asked to take part. All translators were required to work at the law firm's offices so as to preserve confidentiality. Mere translation students worked side by side with newly accredited professionals and journeymen with long years of experience. The more able quickly became aware that much of the material was far too difficult for their less experienced colleagues. No consistent attempt was made to create or distribute glossaries. Wildly differing wages were paid to translators, with little connection to their ability. Several translation agencies were caught up in a feverish battle to handle most of the work and desperately competed to find translators.
No one knows the quality of the final product, but it cannot have been routinely high. Some translators and agencies have still not been fully paid. As the deadline drew closer, more and more boxes of documents appeared. And as the final blow, the opposing company's law firm also came onto the scene with boxes of its own documents that needed translation. But these newcomers imposed one nearly impossible condition, also for reasons of confidentiality: no one who had translated for the first law firm would be permitted to translate for them.
Now let us consider this true-life tale, which occurred just three months ago, and see how—or whether—MT could have handled things better, as is sometimes claimed. Let's be generous and remove one enormous obstacle at the start by assuming that all these cases of documents were in fact in machine-readable form (which, of course, they weren't). Even if we accord MT this ample handicap, there are still a number of problems it would have had trouble coping with:
1. How could a sufficient number of competent post-editors be found or trained before the deadline?
2. How could a sufficiently large and accurate MT dictionary be compiled before the deadline? Doesn't creating such a dictionary require finishing the job first and then saving it for the next job, in the hope that it will be similar ?
3. The simpler Mom & Pop store & smaller agency structure of the human translation world was nonetheless able to field at least some response to this challenge because of its large slack capacity. Would an enormously powerful and expensive mainframe computer have the same slack capacity, i.e., could it be kept inactive for long periods of time until such emergencies occurred? If so, how would this be reflected in the prices charged for its services?
4. How would MT companies have dealt with the secrecy requirement, that translation must be done in the law firm's office?
5. How would an MT Company comply with the demand of the second law firm, that the same post-editors not be used, and still land the job?
6. Supposing the job proved so enormous that two MT firms had to be hired—assuming they used different systems, different glossaries, different post-editors, how could they have collaborated without creating even more work and confusion?
Larger Philosophical Questions
Is it in any final sense a reasonable assumption, as many believe, that progress in MT can be gradual and cumulative in scope until it finally comes to a complete mastery of the problem? In other words, is there a numerical process by which one first masters 3% of all knowledge and vocabulary building processes with 85% accuracy, then 5% with 90% accuracy, and so on until one reaches 99% with 99% accuracy? Is this the whole story of the relationship between knowledge and language, or are there possibly other factors involved, making it possible for reality to manifest itself from several unexpected angles at once. In other words, are we dealing with language as a linear entity when it is in fact a multi-dimensional one?
Einstein maintained that he didn't believe God was playing dice with the universe. Is it possible that by using AI rule-firing techniques with their built-in certainty and confidence values, computational linguists are playing dice with the meaning of the that universe?
It would be possible to design a set of "Turing Tests" to gauge the performance of various MT systems as compared with human translation skills. The point of such a process, as with all Turing Tests, would be to determine if human referees could tell the difference between human and machine output. All necessary safeguards, handicaps, alternate referees, and double blind procedures could be devised, provided the will to take part in such tests actually existed. True definitions for cost, speed, accuracy, and post-editing needs might all have at least a chance of being estimated as a result of such tests. What are the chances of their taking place some time in the near future?
"Computerization is the first stage of the industrial revolution that hasn't made work simpler." Does this statement, paraphrased from a book by a Harvard Business School professor, (2) have any relevance for MT? Is it correct to state that several current MT systems actually add one or more levels of difficulty to the translation process before making it any easier?
While translators may not be able to articulate precisely what kind of interface for translation they most desire, they can certainly state with great certainty what they do NOT want. What they do not want is an interface that is any of the following:
harder to learn and use than conventional translation;
more likely to make mistakes than the above;
lending less prestige than the above;
less well paid than the above.
Are these also concerns for MT developers?
What real work has been done in the AI field in terms of treating translation as a Knowledge Domain and translators as Domain Experts and pairing them off with Knowledge Engineers? What qualifications were sought in either the DE's or the KE's?
Are MT developers using the words "asymptote" and "asymptotic" in their correct mathematical sense, or are they rather using them as buzzwords to impart a false air of mathematical precision to their work? Is the curve their would-be asymptote steadily approaching a representation of FAHQT or something reasonably similar, or could it just turn out to be the edge of a semanto-linguistic Butterfly Effect drawing them inexorably into what Shannon and Weaver recognized as entropy, perhaps even into true Chaos?
Must not all translation, including MT, be recognized as a subset of two far larger sets, namely writing and human mediation? In the first case, does it not therefore become pointless to maintain that there are no accepted standards for what constitutes a "good translation," when of course there are also no accepted standards for what constitutes "good writing?" Or for that matter, no accepted standards for what constitutes "correct writing practices," since all major publications and publishing houses have their own in-house style manuals, with no two in total agreement, either here or in England. And is not translation also a specialized subset of a more generalized form of "mediation," merely employing two natural languages instead of one? In which case, may it belong to the same superset which includes "explaining company rules to new employees," public relations and advertising, or choosing exactly the right time to tell Uncle Louis you're marrying someone he disapproves of?
Are not the only real differences between foreign language translation and such upscale mediation that two languages are involved and the context is usually more limited? In either case (or in both together), what happens if all the complexities that can arise from superset activities descend into the subset and also become "translation problems?" at any time? How does MT deal with either of these cases?
Does the following reflection by Wittgenstein apply to MT: "A sentence is given me in code together with the key. Then of course in one way everything required for understanding the sentence has been given me. And yet I should answer the question `Do you understand this sentence?': No, not yet; I must first decode it. And only when e.g. I had translated it into English would I say `Now I understand it.'
"If now we raise the question `At what moment of translating do I understand the sentence? we shall get a glimpse into the nature of what is called `understanding.'" To take Wittgenstein's example one step further, if MT is used, at what moment of translation does what person or entity understand the sentence? When does the system understand it? How about the hasty post-editor? And what about the translation's target audience, the client? Can we be sure that understanding has taken place at any of these moments? And if understanding has not taken place, has translation?
Practical Suggestions for the Future
1. The process of consultation and cooperation between working translators and MT specialists which has begun here today should be extended into the future through the appointment of Translators in Residence in university and corporate settings, continued lectures and workshops dealing with these themes on a national and international basis, and greater consultation between them in all matters of mutual concern.
2. In the past, many legislative titles for training and coordinating workers have gone unused during each Congressional session in the Department of Labor, HEW, and Commerce. If there truly is a need for retraining translators to use MT and CAT products, it behooves system developers—and might even benefit them financially—to find out if such funding titles can be used to help train translators in the use of truly viable MT systems.
3. It should be the role of an organization such as MT Summit III to launch a campaign aimed at helping people everywhere to understand what human translation and machine translation can and cannot do so as to counter a growing trend towards fast-word language consumption and use.
4. Concomitantly, those present at this Conference should make their will known on an international scale that there is no place in the MT Community for those who falsify the facts about the capabilities of either MT or human translators. The fact that foreign language courses, both live and recorded, have been deceitfully marketed for decades should not be used as an excuse to do the same with MT. I have appended a brief Code of Ethics document for discussion of this matter.
5. Since AI and expert systems are on the lips of many as the next direction for MT, a useful first step in this direction might be the creation of a simple expert system which prospective clients might use to determine if their translation needs are best met by MT, human translation, or some combination of both. I would be pleased to take part in the design of such a program.
DRAFT CODE OF ETHICS:
1. No claims about existing or pending MT products should be made which indicate that MT can reduce the number of human translators or the total cost of translation work unless all costs for the MT project have been scrupulously revealed, including the total price for the system, fees or salaries for those running it, training costs for such workers, training costs for additional pre-editors or post-editors including those who fail at this task, and total costs of amortization over the full period of introducing such a system.
2. No claims should be made for any MT system in terms of "percentage of accuracy," unless this figure is also spelled out in terms of number of errors per page. Any unwillingness to recognize errors as errors shall be considered a violation of this condition, except in those cases where totally error-free work is not required or requested.
3. No claim should be made that any MT system produces "better-quality output" than human translators unless such a claim has been thoroughly quantified to the satisfaction of all parties. Any such claim should be regarded as merely anecdotal until proved otherwise.
4. Researchers and developers should devote serious study to the issue of whether their products might generate less sales resistance, public confusion, and resentment from translators if the name of the entire field were to be changed from "machine translation" or "computer translation" to "computer assisted language conversion."
5. The computer translation industry should bear the cost of setting up an equitably balanced committee of MT workers and translators to oversee the functioning of this Code of Ethics.
6. Since translation is an intrinsically international industry, this Code of Ethics must also be international in its scope, and any company violating its tenets on the premise that they are not valid in its country shall be considered in violation of this Code. Measures shall be taken to expose and punish habitual offenders.
Respectfully Submitted by
Alex Gross, Co-Director
Cross-Cultural Research Projects
alexilen@sprynet.com
NOTES:
(1) Kimmo Kettunen, in a letter to Computational Linguistics, vol. 12, No. 1, January-March, 1986
(2) (2) Shoshana Zuboff: In the Age of the Smart Machine: The Future of Work and Power, Basic Books, 1991.
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
http://language.home.sprynet.com/
alexilen@sprynet.com
Original and Supplementary Questions
Submitted to the MT Summit III Conference,
Washington, 1991
Here are the original questions for this panel as submitted to the speakers:
1. At the last MT Summit, Martin Kay stated that there should be "greater attention to empirical studies of translation so that computational linguists will have a better idea of what really goes on in translation and develop tools that will be more useful for the end user." Does this mean that there has been insufficient input into MT processes by translators interested in MT? Does it mean that MT developers have failed to study what translating actually entails and how translators go about their task? If either of these is true, then to what extent and why? New answers and insights for the MT profession could arise from hearing what human translators with an interest in the development of MT have to say about these matters. It may well turn out that translators are the very people best qualified to determine what form their tools should take, since they are the end users.
2. Is there a specifically "human" component in the translation process which MT experts have overlooked? Is it reasonable for theoreticians to envision setting up predictable and generic vocabularies of clearly defined terms, or could they be overlooking a deep-seated human tendency towards some degree of ambiguity—indeed, in those many cases where not all the facts are known, an inescapably human reliance on it? Are there any viable MT approaches to duplicate what human translators can provide in such cases, namely the ability to bridge this ambiguity gap and improvise personalized, customized case-specific subtleties of vocabulary, depending on client or purpose? Could this in fact be a major element of the entire translation process? Alternately, are there some more boring "machine-like" aspects of translation where the computer can help the translator, such as style and consistency checking?
3. How can the knowledge of practicing translators best be integrated into current MT research and working systems? Is it to be assumed that they are best employed as prospective end-users working out the bugs in the system, or is there also a place for them during the initial planning phases of such systems? Can they perhaps as users be the primary developers of the system?
4. Many human translators, when told of the quest to have machines take over all aspects of translation, immediately reply that this is impossible and start providing specific instances which they claim a machine system could never handle. Are such reactions merely the final nerve spasms of a doomed class of technicians awaiting superannuation, or are these translators in fact enunciating specific instances of a general law as yet not fully articulated?
Since we now hear claims suggesting that FAHQT is creeping in again through the back door, it seems important to ask whether there has in fact ever been sufficient basic mathematical research, much less algorithmic underpinnings, by the MT Community to determine whether FAHQT, or anything close to it, can be achieved by any combination of electronic stratagems (transfer, AI, neural nets, Markov models, etc.).
Must translators forever stand exposed on the firing line and present their minds and bodies to a broadside of claims that the next round of computer advances will annihilate them as a profession? Is this problem truly solvable in logical terms, or is it in fact an intractable, undecidable, or provably unsolvable question in terms of "Computable Numbers" as set out by Turing, based on the work of Hilbert and Goedel? A reasonable answer to this question could save boards of directors and/or government agencies a great deal of time and money.
SUPPLEMENTAL QUESTIONS:
It was also envisioned that a list of Supplemental Questions would be prepared and distributed not only to the speakers but everyone attending our panel, even though not all of these questions could be raised during the session, so as to deepen our discussion and provide a lasting record of these issues.
FAHQT: Pro and Con
Consider the following observation on FAHQT: "The ideal notion of fully automatic high quality translation (FAHQT) is still lurking behind the machine translation paradigm: it is something that MT projects want to reach." (1) Is this a true or a false observation?
Is FAHQT merely a matter of time and continued research, a direct and inevitable result of a perfectly asymptotic process?
Will FAHQT ever be available on a held-held calculator-sized computer? If not, then why not?
To what extent is the belief in the feasibility of FAHQT a form of religion or perhaps akin to a belief that a perpetual motion device can be invented?
Technical Linguistic Questions
Let us suppose a writer has chosen to use Word C in a source text because s/he did not wish to use Word A or Word B, even though all three are shown as "synonyms." It turns out that all three of these words overlap and semantically interrelate quite differently in the target language. How can MT handle such an instance, fairly frequently found in legal and diplomatic usage?
Virtually all research in both conventional and computational linguistics has proceeded from the premise that language can be represented and mapped as a linear entity and is therefore eminently computable. What if it turns out that language in fact occupies a virtual space as a multi-dimensional construct, including several fractal dimensions, involving all manner of non-linear turbulence, chaos, and Butterfly Effects?
Post-Editors and Puppeteers
Let's assume you saw an ad for an Automatic Electronic Puppeteer that guaranteed to create and produce endless puppet plays in your own living room. There would be no need for a puppeteer to run the puppets and no need for you even to script the plays, though you would have the freedom to intervene in the action and change the plot as you wished. Since the price was acceptable, you ordered this system, but when it arrived, you found that it required endless installation work and calls to the manufacturers to get it working. But even then, you discovered that the number of plays provided was in fact quite limited, your plot change options even more so, and that the movements of the puppets were jerky and unnatural. When you complained, you were referred to fine print in the docs telling you that to make the program work better, you would have to do one of two things: 1) master an extremely complex programming language or 2) hire a specially trained puppeteer to help you out with your special needs and to be on hand during your productions to make the puppets move more naturally. Does this description bear any resemblance to the way MT has functioned and been promoted in recent years?
A Practical Example
Despite many presentations on linguistic, electronic and philosophical aspects of MT at this conference, one side of translation has nonetheless gone unexplored. It has to do with how larger translation projects actually arise and are handled by the profession. The following story shows the world of human translation at close to its worst, and it might be imagined at first glance that MT could easily do a much better job and simply take over in such situations, which are far from atypical in the world of translation. But, as we shall see, such appearances may be deceptive. To our story:
A French electrical firm was recently involved in a hostile take-over bid and law suit with its American counterpart. Large numbers of boxes and drawers full of documents all had to be translated into English by an almost impossible deadline. Supervision of this work was entrusted to a paralegal assistant in the French company's New York law firm. This person had no previous knowledge of translation. The documents ran the gamut from highly technical electrical texts and patents, records of previous law suits, company correspondence, advertisements, product documentation, speeches by the Company's directors, etc.
Almost every French-to-English translator in the NYC area was asked to take part. All translators were required to work at the law firm's offices so as to preserve confidentiality. Mere translation students worked side by side with newly accredited professionals and journeymen with long years of experience. The more able quickly became aware that much of the material was far too difficult for their less experienced colleagues. No consistent attempt was made to create or distribute glossaries. Wildly differing wages were paid to translators, with little connection to their ability. Several translation agencies were caught up in a feverish battle to handle most of the work and desperately competed to find translators.
No one knows the quality of the final product, but it cannot have been routinely high. Some translators and agencies have still not been fully paid. As the deadline drew closer, more and more boxes of documents appeared. And as the final blow, the opposing company's law firm also came onto the scene with boxes of its own documents that needed translation. But these newcomers imposed one nearly impossible condition, also for reasons of confidentiality: no one who had translated for the first law firm would be permitted to translate for them.
Now let us consider this true-life tale, which occurred just three months ago, and see how—or whether—MT could have handled things better, as is sometimes claimed. Let's be generous and remove one enormous obstacle at the start by assuming that all these cases of documents were in fact in machine-readable form (which, of course, they weren't). Even if we accord MT this ample handicap, there are still a number of problems it would have had trouble coping with:
1. How could a sufficient number of competent post-editors be found or trained before the deadline?
2. How could a sufficiently large and accurate MT dictionary be compiled before the deadline? Doesn't creating such a dictionary require finishing the job first and then saving it for the next job, in the hope that it will be similar ?
3. The simpler Mom & Pop store & smaller agency structure of the human translation world was nonetheless able to field at least some response to this challenge because of its large slack capacity. Would an enormously powerful and expensive mainframe computer have the same slack capacity, i.e., could it be kept inactive for long periods of time until such emergencies occurred? If so, how would this be reflected in the prices charged for its services?
4. How would MT companies have dealt with the secrecy requirement, that translation must be done in the law firm's office?
5. How would an MT Company comply with the demand of the second law firm, that the same post-editors not be used, and still land the job?
6. Supposing the job proved so enormous that two MT firms had to be hired—assuming they used different systems, different glossaries, different post-editors, how could they have collaborated without creating even more work and confusion?
Larger Philosophical Questions
Is it in any final sense a reasonable assumption, as many believe, that progress in MT can be gradual and cumulative in scope until it finally comes to a complete mastery of the problem? In other words, is there a numerical process by which one first masters 3% of all knowledge and vocabulary building processes with 85% accuracy, then 5% with 90% accuracy, and so on until one reaches 99% with 99% accuracy? Is this the whole story of the relationship between knowledge and language, or are there possibly other factors involved, making it possible for reality to manifest itself from several unexpected angles at once. In other words, are we dealing with language as a linear entity when it is in fact a multi-dimensional one?
Einstein maintained that he didn't believe God was playing dice with the universe. Is it possible that by using AI rule-firing techniques with their built-in certainty and confidence values, computational linguists are playing dice with the meaning of the that universe?
It would be possible to design a set of "Turing Tests" to gauge the performance of various MT systems as compared with human translation skills. The point of such a process, as with all Turing Tests, would be to determine if human referees could tell the difference between human and machine output. All necessary safeguards, handicaps, alternate referees, and double blind procedures could be devised, provided the will to take part in such tests actually existed. True definitions for cost, speed, accuracy, and post-editing needs might all have at least a chance of being estimated as a result of such tests. What are the chances of their taking place some time in the near future?
"Computerization is the first stage of the industrial revolution that hasn't made work simpler." Does this statement, paraphrased from a book by a Harvard Business School professor, (2) have any relevance for MT? Is it correct to state that several current MT systems actually add one or more levels of difficulty to the translation process before making it any easier?
While translators may not be able to articulate precisely what kind of interface for translation they most desire, they can certainly state with great certainty what they do NOT want. What they do not want is an interface that is any of the following:
harder to learn and use than conventional translation;
more likely to make mistakes than the above;
lending less prestige than the above;
less well paid than the above.
Are these also concerns for MT developers?
What real work has been done in the AI field in terms of treating translation as a Knowledge Domain and translators as Domain Experts and pairing them off with Knowledge Engineers? What qualifications were sought in either the DE's or the KE's?
Are MT developers using the words "asymptote" and "asymptotic" in their correct mathematical sense, or are they rather using them as buzzwords to impart a false air of mathematical precision to their work? Is the curve their would-be asymptote steadily approaching a representation of FAHQT or something reasonably similar, or could it just turn out to be the edge of a semanto-linguistic Butterfly Effect drawing them inexorably into what Shannon and Weaver recognized as entropy, perhaps even into true Chaos?
Must not all translation, including MT, be recognized as a subset of two far larger sets, namely writing and human mediation? In the first case, does it not therefore become pointless to maintain that there are no accepted standards for what constitutes a "good translation," when of course there are also no accepted standards for what constitutes "good writing?" Or for that matter, no accepted standards for what constitutes "correct writing practices," since all major publications and publishing houses have their own in-house style manuals, with no two in total agreement, either here or in England. And is not translation also a specialized subset of a more generalized form of "mediation," merely employing two natural languages instead of one? In which case, may it belong to the same superset which includes "explaining company rules to new employees," public relations and advertising, or choosing exactly the right time to tell Uncle Louis you're marrying someone he disapproves of?
Are not the only real differences between foreign language translation and such upscale mediation that two languages are involved and the context is usually more limited? In either case (or in both together), what happens if all the complexities that can arise from superset activities descend into the subset and also become "translation problems?" at any time? How does MT deal with either of these cases?
Does the following reflection by Wittgenstein apply to MT: "A sentence is given me in code together with the key. Then of course in one way everything required for understanding the sentence has been given me. And yet I should answer the question `Do you understand this sentence?': No, not yet; I must first decode it. And only when e.g. I had translated it into English would I say `Now I understand it.'
"If now we raise the question `At what moment of translating do I understand the sentence? we shall get a glimpse into the nature of what is called `understanding.'" To take Wittgenstein's example one step further, if MT is used, at what moment of translation does what person or entity understand the sentence? When does the system understand it? How about the hasty post-editor? And what about the translation's target audience, the client? Can we be sure that understanding has taken place at any of these moments? And if understanding has not taken place, has translation?
Practical Suggestions for the Future
1. The process of consultation and cooperation between working translators and MT specialists which has begun here today should be extended into the future through the appointment of Translators in Residence in university and corporate settings, continued lectures and workshops dealing with these themes on a national and international basis, and greater consultation between them in all matters of mutual concern.
2. In the past, many legislative titles for training and coordinating workers have gone unused during each Congressional session in the Department of Labor, HEW, and Commerce. If there truly is a need for retraining translators to use MT and CAT products, it behooves system developers—and might even benefit them financially—to find out if such funding titles can be used to help train translators in the use of truly viable MT systems.
3. It should be the role of an organization such as MT Summit III to launch a campaign aimed at helping people everywhere to understand what human translation and machine translation can and cannot do so as to counter a growing trend towards fast-word language consumption and use.
4. Concomitantly, those present at this Conference should make their will known on an international scale that there is no place in the MT Community for those who falsify the facts about the capabilities of either MT or human translators. The fact that foreign language courses, both live and recorded, have been deceitfully marketed for decades should not be used as an excuse to do the same with MT. I have appended a brief Code of Ethics document for discussion of this matter.
5. Since AI and expert systems are on the lips of many as the next direction for MT, a useful first step in this direction might be the creation of a simple expert system which prospective clients might use to determine if their translation needs are best met by MT, human translation, or some combination of both. I would be pleased to take part in the design of such a program.
DRAFT CODE OF ETHICS:
1. No claims about existing or pending MT products should be made which indicate that MT can reduce the number of human translators or the total cost of translation work unless all costs for the MT project have been scrupulously revealed, including the total price for the system, fees or salaries for those running it, training costs for such workers, training costs for additional pre-editors or post-editors including those who fail at this task, and total costs of amortization over the full period of introducing such a system.
2. No claims should be made for any MT system in terms of "percentage of accuracy," unless this figure is also spelled out in terms of number of errors per page. Any unwillingness to recognize errors as errors shall be considered a violation of this condition, except in those cases where totally error-free work is not required or requested.
3. No claim should be made that any MT system produces "better-quality output" than human translators unless such a claim has been thoroughly quantified to the satisfaction of all parties. Any such claim should be regarded as merely anecdotal until proved otherwise.
4. Researchers and developers should devote serious study to the issue of whether their products might generate less sales resistance, public confusion, and resentment from translators if the name of the entire field were to be changed from "machine translation" or "computer translation" to "computer assisted language conversion."
5. The computer translation industry should bear the cost of setting up an equitably balanced committee of MT workers and translators to oversee the functioning of this Code of Ethics.
6. Since translation is an intrinsically international industry, this Code of Ethics must also be international in its scope, and any company violating its tenets on the premise that they are not valid in its country shall be considered in violation of this Code. Measures shall be taken to expose and punish habitual offenders.
Respectfully Submitted by
Alex Gross, Co-Director
Cross-Cultural Research Projects
alexilen@sprynet.com
NOTES:
(1) Kimmo Kettunen, in a letter to Computational Linguistics, vol. 12, No. 1, January-March, 1986
(2) (2) Shoshana Zuboff: In the Age of the Smart Machine: The Future of Work and Power, Basic Books, 1991.
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Friday, May 22, 2009
Machine Translation: Ingredients for Productive and Stable MT deployments - Part 3
By Mike Dillinger,
PhD & Laurie Gerber,
Translation Optimization Partners
This is the final part of the first in a new series of articles on how to achieve successful deployments of machine translation in various use cases. Different types of source documents and different uses for the translations lead to varying approaches to automation. In the first part of this article, we talked about why it is so important to automate translation of knowledge bases.
Pioneering companies have shown that automating translation is the best way to make product knowledge bases available to global markets. Customers consistently rate machine translated and English technical information as equally useful. A typical installation for automatic translation weaves together stored human translations that you already paid for and machine-translated new sentences to get the best of both approaches.
Steps to Success
Set your expectations. The documents in knowledge bases have distinctive characteristics when compared to other product support documentation, starting with the fact that they are written by engineers. These engineers may be experts in a technical domain, but they haven’t ever been trained in technical writing and are often not native speakers of English.
High-speed, high-volume translation simply cannot be perfect, no matter what mix of humans and machines we use. This is why emphasis in evaluation has shifted to measuring translation "usefulness", rather than absolute linguistic quality. The effective benchmark is no longer whether expert linguists detect the presence or absence of errors. The new, more practical criterion is whether non-expert customers find a translation to be valuable, in spite of its linguistic imperfections. We see time and time again that they most certainly do. You’ll confirm this with your own customers when you do beta testing of your installation.
Set realistic expectations for automatic translation: there will be many errors, but customers will find the translations useful anyway.
Start small. Start with only one language and focus on a single part of your content. Success is easier to achieve when you start with a single "beachhead" language. Starting small has little to do with machine translation and much more to do with simplifying change management: work out the details on a small scale before approaching a bigger project.
In our consulting practice, we’ve seen two main ways of deciding where to start: focusing on customer needs or on internal processes. For the customer-needs approach, your decision is guided by questions like: Which community of customers suffers most from the lack of local- language materials? Which community costs you the most in support calls? In translation expenses? Which has the least web content already translated? The decision is guided by the most important customer support issues.
For the internal-process approach, your decision is guided by questions like: Which languages are we most familiar with? Which do we have most translations for?
What languages are our staff strongest in? Which in-country groups collaborate best? The decision in this case is to build on your strengths.
Start small to build a robust, Scalable process.
Choose an MT vendor. The International Association for Machine Translation sponsors a Compendium of Translation Software that is updated regularly. In it, you can find companies large and small that have developed a range of products for translating many languages. You will see companies such as Language Weaver, Systran, ProMT, AppTek, SDL, and many others. How can you choose between them?
Linguistic quality of the translations is the first thing that many clients want to look at. Remember that you won’t offer to your customers what you see during initial testing. And even a careful linguistic analysis of translation output quality may not tell you much about whether the system can help you achieve your business goals. Evaluation of translation automation options is much more complex than having a translator check some sentences. You may want to hire a consultant to help with evaluation, while bringing your staff up to speed on the complexities of multilingual content.
For knowledge-base translation, scalability and performance are important issues to discuss with each vendor. Most vendors can meet your criteria for response time or throughput, but they may need very different hardware to do so.
You can narrow down or prioritize the list of vendors by using other criteria:
* Choose vendors who can translate the specific languages that you are interested in. If you want to translate into Turkish or Indonesian, you won’t have as many options as into Spanish or Chinese.
* Check that you have what the vendor needs. Some MT systems (from Language Weaver, for example) need a large collection of documents together with their translations. If you aren’t translating your documents by hand already, then you may not have enough data for this kind of system. Other MT systems (from Systran or ProMT, for example) can use this kind of data, but don’t require you to have it.
* Check how many other clients have used the product for knowledge base translation – to judge how much experience the vendor has with your specific use case. The best-known vendors have experience with dozens of different installations, so try to get information about the installations that are most similar to yours. Ask, too, for referrals to existing customers who can share their stories and help prepare you better for the road ahead. MT is changing rapidly, so you shouldn’t reject a product only because it’s new. But the way that these questions are addressed or dismissed will give some insight into how the vendor will respond to your issues.
* Think through how you will approach on-going improvements after your MT system is installed. If you want to actively engage in monitoring and improving translation quality, some MT vendors (Systran of ProMT, for example) offer a range of tools to help. Other MT vendors (Language Weaver, for example) will periodically gather your new human translations and use them to update the MT system for you, with some ability to correct errors on your own.
Of course, price and licensing terms will be important considerations. Be aware that each vendor calculates prices differently: they may take into account how many servers you need, how many language pairs (ex: English>Spanish and Spanish>English is one language pair), how many language directions (ex: English>Spanish and Spanish>English are two language directions), how many people will use the system, how many different use cases, additional tools you may need, the response times or throughput that you need, etc. Experience shows that the best approach is to make a detailed description of what you want to do and then ask for quotes.
Adapt the MT system to your specific needs before you go live. Whatever MT system you choose, you or the vendor (or both) will have to adapt it to your specific vocabulary and writing style. Just as human translators need extra training for new topics and new technical vocabulary, MT systems need to have the vocabulary in your documents to translate them well. Some vendors call this process of adapting the MT system to your specific needs training, others call it customization.
An MT system starts with a generic knowledge of generic English. Your knowledge base, on the other hand, has thousands of special words for your unique products as well as the jargon that your engineers and sales people have developed over many years. The goal is to bridge this linguistic gap between your organization’s writing and generic English.
Different vendors take different approaches to bridging this gap. Some MT systems ("statistical MT" – from Language Weaver, for example) take large amounts of your translated documents and feed them into tools that quickly build statistical models of your words and how they’re usually translated. If you don’t have a sizeable collection of translated documents, though, it’s difficult to build a good statistical MT system. All MT systems can make use of your existing terminology lists and glossaries with your special words and jargon. And many MT systems, from Systran or ProMT, for example can use your translated documents to extract dictionaries directly from translated documents. Hybrid MT systems, which are just emerging in the market, also build statistical models, to combine the best of both techniques. Hybrid MT systems are more practical when you don’t have a sizeable collection of translated documents to start from.
Go live. Do this in stages, starting with an internal test by the main stakeholders. Then move into "beta" testing with a password-protected site for a handful of real product users. Be sure to have a disclaimer that openly announces that the document is an automated translation and may contain errors. (At the same time, you will want to promote the availability of the content in the user’s language as a new benefit.) Actively seek out their feedback to identify specific problems, and address the ones that they cite most frequently. At this stage, your users may mention that there are errors in the translation; try to get them to identify specific words and/or sentences.
In knowledge-base deployments, a small proportion of the content (<10%) is widely read and the vast majority of the content is rarely read. The current best practice is to establish a threshold of popularity or minimum hit rate that will trigger human translation of the few most-popular articles for a better overall customer experience.
This is the time to do a reality check: offer a feedback box on each translated page. It is most helpful if you ask for the same feedback on your source-language pages for comparison. If the translated page is rated much lower than the original page, then the difference may signal a problem in translation.
Keep improving quality. Inevitably, products and jargon will change and you will identify recurring errors. Translation quality management is an on-going activity with two main parts: managing quality of the original documents and managing the parts of the MT system.
We’ll leave discussion of document quality management for a future article. When engineers respond to emergent problems with knowledge-base articles, it is not practical to impose stringent authoring guidelines. But you can encourage them to work from a standard terminology list (terms that the customers know, which may be different from terms that the engineers use). This will make the source-language documents easier to understand, and will improve the translations, as well.
For rule-based or hybrid MT systems, you will want to manage (or outsource management of) key components like the dictionary. As errors or changes arise, updating the dictionary will improve translation quality. For statistical MT systems, you will want to manage carefully any human translated content and "feed" it into the system. The more data you use, the better these systems get.
Repeat for another language. With the first language, you will work out the kinks in your process. Once you see how very appreciative the customers are for content in their own language, you can get to work on the next language. Now you know the drill, you know the tools, and you know what to look for. The next language will take you only 25% of the effort you put into deploying the first one.
Links
Will Burgett & Julie Chang (Intel). AMTA Waikiki, 2008. The Triple-Advantage Factor of MT: Cost, Time-to-Market, and FAUT.
Priscilla Knoble & Francis Tsang (Adobe). Hitting the Ground Running in New Markets: Do Your Global Business Processes Measure Up? LISA San Francisco, 2008.
Chris Wendt (Microsoft). AMTA Waikiki, 2008. Large-scale deployment of statistical machine translation: Example Microsoft.
Authors:
Mike Dillinger, PhD and Laurie Gerber are Translation Optimization Partners We are an independent consultancy specialized in translation processes and technologies. Both Principals are leaders in translation automation and past Presidents of the Association for Machine Translation in the Americas, with 40 years’ experience in creating and managing technical content, developing translation technologies, and deploying translation processes. We develop solutions in government and commercial environments to meet the needs of translation clients and content users. Our offices are in Silicon Valley and San Diego. Contact us for further information:
Mike Dillinger mike [at] mikedillinger . com
Laurie Gerber gerbl [at] pacbell . net
Mike needs more places to grind this axe: Authors and authoring are often treated as an unimportant afterthought, in spite of the central role of high-quality content in brand management, marketing, sales, training, customer satisfaction, customer support, operational communications, and everything else.
Published - April 2009
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
PhD & Laurie Gerber,
Translation Optimization Partners
This is the final part of the first in a new series of articles on how to achieve successful deployments of machine translation in various use cases. Different types of source documents and different uses for the translations lead to varying approaches to automation. In the first part of this article, we talked about why it is so important to automate translation of knowledge bases.
Pioneering companies have shown that automating translation is the best way to make product knowledge bases available to global markets. Customers consistently rate machine translated and English technical information as equally useful. A typical installation for automatic translation weaves together stored human translations that you already paid for and machine-translated new sentences to get the best of both approaches.
Steps to Success
Set your expectations. The documents in knowledge bases have distinctive characteristics when compared to other product support documentation, starting with the fact that they are written by engineers. These engineers may be experts in a technical domain, but they haven’t ever been trained in technical writing and are often not native speakers of English.
High-speed, high-volume translation simply cannot be perfect, no matter what mix of humans and machines we use. This is why emphasis in evaluation has shifted to measuring translation "usefulness", rather than absolute linguistic quality. The effective benchmark is no longer whether expert linguists detect the presence or absence of errors. The new, more practical criterion is whether non-expert customers find a translation to be valuable, in spite of its linguistic imperfections. We see time and time again that they most certainly do. You’ll confirm this with your own customers when you do beta testing of your installation.
Set realistic expectations for automatic translation: there will be many errors, but customers will find the translations useful anyway.
Start small. Start with only one language and focus on a single part of your content. Success is easier to achieve when you start with a single "beachhead" language. Starting small has little to do with machine translation and much more to do with simplifying change management: work out the details on a small scale before approaching a bigger project.
In our consulting practice, we’ve seen two main ways of deciding where to start: focusing on customer needs or on internal processes. For the customer-needs approach, your decision is guided by questions like: Which community of customers suffers most from the lack of local- language materials? Which community costs you the most in support calls? In translation expenses? Which has the least web content already translated? The decision is guided by the most important customer support issues.
For the internal-process approach, your decision is guided by questions like: Which languages are we most familiar with? Which do we have most translations for?
What languages are our staff strongest in? Which in-country groups collaborate best? The decision in this case is to build on your strengths.
Start small to build a robust, Scalable process.
Choose an MT vendor. The International Association for Machine Translation sponsors a Compendium of Translation Software that is updated regularly. In it, you can find companies large and small that have developed a range of products for translating many languages. You will see companies such as Language Weaver, Systran, ProMT, AppTek, SDL, and many others. How can you choose between them?
Linguistic quality of the translations is the first thing that many clients want to look at. Remember that you won’t offer to your customers what you see during initial testing. And even a careful linguistic analysis of translation output quality may not tell you much about whether the system can help you achieve your business goals. Evaluation of translation automation options is much more complex than having a translator check some sentences. You may want to hire a consultant to help with evaluation, while bringing your staff up to speed on the complexities of multilingual content.
For knowledge-base translation, scalability and performance are important issues to discuss with each vendor. Most vendors can meet your criteria for response time or throughput, but they may need very different hardware to do so.
You can narrow down or prioritize the list of vendors by using other criteria:
* Choose vendors who can translate the specific languages that you are interested in. If you want to translate into Turkish or Indonesian, you won’t have as many options as into Spanish or Chinese.
* Check that you have what the vendor needs. Some MT systems (from Language Weaver, for example) need a large collection of documents together with their translations. If you aren’t translating your documents by hand already, then you may not have enough data for this kind of system. Other MT systems (from Systran or ProMT, for example) can use this kind of data, but don’t require you to have it.
* Check how many other clients have used the product for knowledge base translation – to judge how much experience the vendor has with your specific use case. The best-known vendors have experience with dozens of different installations, so try to get information about the installations that are most similar to yours. Ask, too, for referrals to existing customers who can share their stories and help prepare you better for the road ahead. MT is changing rapidly, so you shouldn’t reject a product only because it’s new. But the way that these questions are addressed or dismissed will give some insight into how the vendor will respond to your issues.
* Think through how you will approach on-going improvements after your MT system is installed. If you want to actively engage in monitoring and improving translation quality, some MT vendors (Systran of ProMT, for example) offer a range of tools to help. Other MT vendors (Language Weaver, for example) will periodically gather your new human translations and use them to update the MT system for you, with some ability to correct errors on your own.
Of course, price and licensing terms will be important considerations. Be aware that each vendor calculates prices differently: they may take into account how many servers you need, how many language pairs (ex: English>Spanish and Spanish>English is one language pair), how many language directions (ex: English>Spanish and Spanish>English are two language directions), how many people will use the system, how many different use cases, additional tools you may need, the response times or throughput that you need, etc. Experience shows that the best approach is to make a detailed description of what you want to do and then ask for quotes.
Adapt the MT system to your specific needs before you go live. Whatever MT system you choose, you or the vendor (or both) will have to adapt it to your specific vocabulary and writing style. Just as human translators need extra training for new topics and new technical vocabulary, MT systems need to have the vocabulary in your documents to translate them well. Some vendors call this process of adapting the MT system to your specific needs training, others call it customization.
An MT system starts with a generic knowledge of generic English. Your knowledge base, on the other hand, has thousands of special words for your unique products as well as the jargon that your engineers and sales people have developed over many years. The goal is to bridge this linguistic gap between your organization’s writing and generic English.
Different vendors take different approaches to bridging this gap. Some MT systems ("statistical MT" – from Language Weaver, for example) take large amounts of your translated documents and feed them into tools that quickly build statistical models of your words and how they’re usually translated. If you don’t have a sizeable collection of translated documents, though, it’s difficult to build a good statistical MT system. All MT systems can make use of your existing terminology lists and glossaries with your special words and jargon. And many MT systems, from Systran or ProMT, for example can use your translated documents to extract dictionaries directly from translated documents. Hybrid MT systems, which are just emerging in the market, also build statistical models, to combine the best of both techniques. Hybrid MT systems are more practical when you don’t have a sizeable collection of translated documents to start from.
Go live. Do this in stages, starting with an internal test by the main stakeholders. Then move into "beta" testing with a password-protected site for a handful of real product users. Be sure to have a disclaimer that openly announces that the document is an automated translation and may contain errors. (At the same time, you will want to promote the availability of the content in the user’s language as a new benefit.) Actively seek out their feedback to identify specific problems, and address the ones that they cite most frequently. At this stage, your users may mention that there are errors in the translation; try to get them to identify specific words and/or sentences.
In knowledge-base deployments, a small proportion of the content (<10%) is widely read and the vast majority of the content is rarely read. The current best practice is to establish a threshold of popularity or minimum hit rate that will trigger human translation of the few most-popular articles for a better overall customer experience.
This is the time to do a reality check: offer a feedback box on each translated page. It is most helpful if you ask for the same feedback on your source-language pages for comparison. If the translated page is rated much lower than the original page, then the difference may signal a problem in translation.
Keep improving quality. Inevitably, products and jargon will change and you will identify recurring errors. Translation quality management is an on-going activity with two main parts: managing quality of the original documents and managing the parts of the MT system.
We’ll leave discussion of document quality management for a future article. When engineers respond to emergent problems with knowledge-base articles, it is not practical to impose stringent authoring guidelines. But you can encourage them to work from a standard terminology list (terms that the customers know, which may be different from terms that the engineers use). This will make the source-language documents easier to understand, and will improve the translations, as well.
For rule-based or hybrid MT systems, you will want to manage (or outsource management of) key components like the dictionary. As errors or changes arise, updating the dictionary will improve translation quality. For statistical MT systems, you will want to manage carefully any human translated content and "feed" it into the system. The more data you use, the better these systems get.
Repeat for another language. With the first language, you will work out the kinks in your process. Once you see how very appreciative the customers are for content in their own language, you can get to work on the next language. Now you know the drill, you know the tools, and you know what to look for. The next language will take you only 25% of the effort you put into deploying the first one.
Links
Will Burgett & Julie Chang (Intel). AMTA Waikiki, 2008. The Triple-Advantage Factor of MT: Cost, Time-to-Market, and FAUT.
Priscilla Knoble & Francis Tsang (Adobe). Hitting the Ground Running in New Markets: Do Your Global Business Processes Measure Up? LISA San Francisco, 2008.
Chris Wendt (Microsoft). AMTA Waikiki, 2008. Large-scale deployment of statistical machine translation: Example Microsoft.
Authors:
Mike Dillinger, PhD and Laurie Gerber are Translation Optimization Partners We are an independent consultancy specialized in translation processes and technologies. Both Principals are leaders in translation automation and past Presidents of the Association for Machine Translation in the Americas, with 40 years’ experience in creating and managing technical content, developing translation technologies, and deploying translation processes. We develop solutions in government and commercial environments to meet the needs of translation clients and content users. Our offices are in Silicon Valley and San Diego. Contact us for further information:
Mike Dillinger mike [at] mikedillinger . com
Laurie Gerber gerbl [at] pacbell . net
Mike needs more places to grind this axe: Authors and authoring are often treated as an unimportant afterthought, in spite of the central role of high-quality content in brand management, marketing, sales, training, customer satisfaction, customer support, operational communications, and everything else.
Published - April 2009
ClientSide News Magazine - www.clientsidenews.com
Corporate Blog of Elite - Professional Translation Services serving ASEAN & East Asia
Subscribe to:
Posts (Atom)




